
Entendendo falhas em cascata e como construir serviços que sabem quebrar
Por que seu sistema precisa saber falhar antes de saber funcionar


Com o avanço da utilização de AI para escrita de código, tenho percebido nos últimos meses vários novos empreendedores (ou builders), se posso chamá-los assim, prototipando e construindo sistemas e aplicações em velocidade assustadora.
Não me entendam mal, eu sou totalmente a favor da AI, utilizo muito no trabalho e também dou risada e concordo com alguns rants do Kelsey Hightower no Linkedin, porque acho que ele tem bons pontos.
É com esse gancho que eu inicio esse texto. Não para criticar o mercado, nem os builders, mas para reforçar que velocidade sem fundamento técnico tem prazo de validade e essa é a real. Seu sistema pode nascer rápido, mas sem uma base sólida, ele não sobrevive por muito tempo.
Uma das grandes “vulnerabilidades” (além as de segurança) hoje em dia é como lidar com falhas. Quanto maior o sistema, ou a quantidade de microsserviços você tem, maior a probabilidade que eles falhem. Novamente, precisamos dessa base fundamental, pois sem ela meu amigo, você está lascado para lidar com falhas sem que seu sistema fique instável.
O que são Falhas em Cascata
Considere um serviço que você administra, ele possui dependências e outros serviços dependem dele.
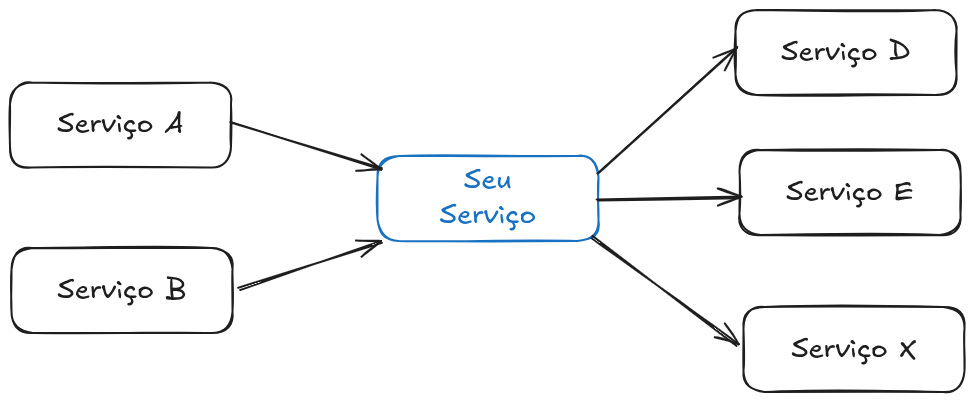
O que acontece caso uma das dependências falhe? Se você não implementar nenhum mecanismo de segurança, provavelmente o seu serviço irá falhar.
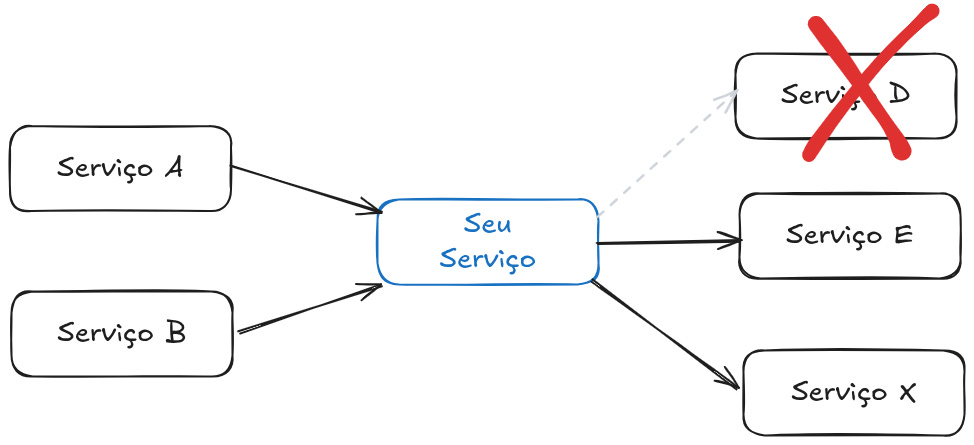
Agora se o seu serviço falha, essa falha pode fazer com que os Serviços A e B também falhem, causando um caos em toda sua aplicação. Muito prazer, o nome disso é falha em cascata.
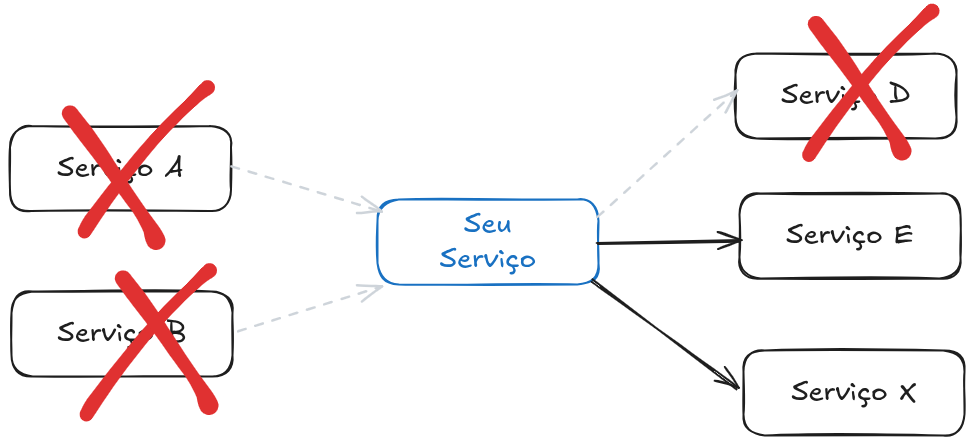
E o que podemos fazer para prevenir isso? Na real é que às vezes não podemos fazer nada, outras vezes um erro em uma dependência crítica simplesmente não tem contorno. Imagine um cenário onde o banco de dados principal está fora do ar, por exemplo, não há mágica que salve uma operação de escrita e seu serviço não vai conseguir realizar o que precisa porque essa dependência falhou, porém, nem sempre esse é o caso e existem várias maneiras de “salvar” seus serviços em caso de uma falha de dependência.
Respondendo a Falhas
Quando um serviço que você depende falha, como você deve responder? A resposta para uma falha de dependência deve ser, previsível, de fácil entendimento e adequada para a situação. Vamos entrar em mais detalhes.
Previsibilidade
Previsibilidade é uma das características mais importantes que um serviço pode ter. Dado um conjunto específico de circunstâncias e requisições, o seu serviço deve sempre produzir respostas que os consumidores consigam antecipar e tratar. Sem isso, cada falha de dependência se transforma em uma surpresa para quem consome o seu serviço, e surpresas são exatamente o combustível das falhas em cascata.
Assim, se uma de suas dependências downstream falhar você consegue gerar uma resposta previsível, que pode tranquilamente ser uma mensagem de erro.
Vale ressaltar que uma resposta de erro não é o mesmo que uma resposta imprevisível. Uma resposta imprevisível é aquela que os serviços consumidores não esperam receber. Já uma resposta de erro é uma resposta válida, informando que não foi possível executar a operação solicitada. Isso são coisas fundamentalmente diferentes.
Imagine o cenário: se o seu serviço de pagamentos recebe uma requisição para cobrar R$50 de um cliente, é esperado que ele retorne uma confirmação com o ID da transação. Essa é uma resposta previsível. Se esse mesmo serviço recebe uma requisição com um ID de cliente inexistente, uma resposta previsível seria um 404 Not Found ou 400 Bad Request. Ambas são respostas previsíveis, pois o serviço que fez a requisição saberá como interpretá-las e reagir.
Agora, uma resposta imprevisível seria se esse mesmo serviço, ao receber uma requisição com um ID de cliente inexistente, retornasse uma confirmação de cobrança com um ID de transação gerado aleatoriamente, como se o pagamento tivesse sido processado com sucesso. Ou pior, retornasse os dados de outro cliente. O consumidor não tem como se preparar para esse tipo de resposta porque ela não faz parte de nenhum cenário esperado. É o tipo de comportamento que transforma uma falha simples em um problema silencioso que só vai ser descoberto dias depois, numa conciliação financeira.
Fácil Entendimento
Aqui é mais simples e direto, fácil entendimento é formatar uma estrutura acordada entre o serviço e os serviços consumidores, ou seja, um contrato onde as respostas devem respeitar seus limites, mesmo quando uma dependência se comporta de forma inesperada.
Violar esse contrato da sua API com seus consumidores só porque uma dependência violou o contrato dela com você é um super anti-pattern. Ao invés disso, garanta que você cobriu todas as possibilidades de resposta do seu serviço, incluindo cenários de falha nas suas dependências.
Um exemplo clássico de violação de contrato é retornar 200 OK quando algo deu errado.
Voltando ao serviço de pagamentos, se o gateway de cobrança começa a falhar e o seu serviço responde 200 OK com uma mensagem de erro no body, o consumidor pode registrar a cobrança como concluída quando ela nunca aconteceu. Um 502 Bad Gateway ou 503 Service Unavailable seria uma resposta compreensível, onde o serviço que fez a requisição saberia exatamente o que fazer.
Respostas Adequadas
As respostas devem refletir o que de fato está acontecendo com o seu serviço, mesmo quando as dependências estão falhando, a resposta precisa fazer sentido dentro do domínio da operação. Retornar “não foi possível processar a cobrança” ou “tente novamente mais tarde” são respostas razoáveis. Retornar um ID de transação fictício ou um valor aleatório, não são.
Isso parece óbvio, mas respostas absurdas causam problemas com mais frequência do que se imagina. Considere o seguinte cenário onde um serviço de conciliação financeira consulta o serviço de pagamentos para obter a lista de todas as cobranças pendentes que precisam ser estornadas. Em condições normais, o serviço retorna a lista correta e os estornos são processados sem problema.
Agora imagine que o serviço de pagamentos está com uma dependência falhando e, em vez de retornar um erro, retorna uma lista vazia, ou pior, retorna a lista completa de transações, sem filtrar as que são pendentes. E o resultado é puro caos! O serviço de conciliação confia nessa resposta e executa estornos em massa, incluindo cobranças que já foram liquidadas. O resultado é um desastre financeiro enorme causado não por uma falha visível, mas por uma resposta que parecia razoável à primeira vista.
Outro cenário perigoso é quando a operação é concluída com sucesso, mas a resposta indica falha. Imagine que o serviço de pagamentos cobra os R$ 50,00 do cliente, o valor é debitado, mas na hora de retornar a confirmação algo dá errado e o serviço responde com um 500 Internal Server Error. O consumidor interpreta que a cobrança não aconteceu e faz um retry. Resultado: o cliente é cobrado duas, três, cinco vezes pelos mesmos R$ 50,00.
Esse é um caso clássico onde a resposta não é adequada ao que de fato aconteceu. A cobrança foi bem-sucedida, mas a resposta disse o contrário. Aqui, mecanismos como idempotência, onde o consumidor envia uma chave única por requisição e o serviço garante que a mesma operação não será executada duas vezes são essenciais para evitar esse tipo de estrago.
Determinando Falhas
Agora que sabemos o básico do básico de como responder a falhas, precisamos determinar quando uma dependência começa a falhar em primeiro lugar. E isso depende de como a falha aconteceu, vou dar alguns exemplos:
Garbled Responses (ou Respostas Confusas)
Direto ao ponto, a resposta foi dada em um formato irreconhecível pelo serviço consumidor, exemplo, você aguarda um array e a resposta chegou em string.
Respostas indicando erro fatal
Aqui a resposta já foi parseada corretamente, indicando um problema ocorreu durante o processamento da requisição. Geralmente, não é uma falha na camada de comunicação, mas com o serviço em si.
No contexto do serviço de pagamentos, seria o equivalente a enviar uma requisição de cobrança com um payload inválido, por exemplo, sem o valor da transação ou com um formato de moeda que o serviço não reconhece. A resposta 400 Bad Request ou 500 Internal Server Error é perfeitamente compreensível, algo deu errado e o serviço consumidor sabe que não deve confiar em nenhum resultado dessa operação.
Resposta compreensível, mas com resultados inesperados
A resposta é compreensível e indica que a operação foi executada sem erros graves, mas os dados retornados não correspondem ao esperado. No serviço de pagamentos, seria como solicitar o extrato de cobranças de um cliente e receber as cobranças de outro. A resposta está bem formatada, o status code é 200 OK, mas o conteúdo está errado. Esse tipo de falha é perigoso porque passa despercebido por validações superficiais.
Resultado fora dos limites esperados
A resposta é compreensível pelo serviço consumidor, a operação foi executada com sucesso, e os dados estão em um formato “razoável”, mas os valores em si não fazem sentido. Usando nosso exemplo de serviço de pagamentos é retornado o total de cobranças pendentes de um cliente e o valor é R$ 9.999,99 para uma assinatura mensal de R$ 49,90. A resposta é válida, parseável e não indica erro, mas está claramente fora dos limites esperados. Sem uma validação de limites no consumidor, esse valor poderia ser cobrado de fato.
A resposta não chegou
A requisição foi enviada, mas nenhuma resposta foi recebida. Isso pode acontecer por um problema de rede, uma falha no serviço ou uma indisponibilidade total. No caso do serviço de pagamentos, o chamador fica sem saber se a cobrança foi efetuada ou não, ou seja, um cenário que exige estratégias como idempotência e retry com backoff para ser tratado de forma segura.
E quando a resposta demorou pra chegar?
A requisição foi enviada e a resposta chegou válida, útil e dentro dos limites esperados. Porém, levou muito mais tempo que o normal. Isso costuma ser um sinal de que o serviço ou a rede está sobrecarregada. No serviço de pagamentos, uma resposta lenta pode significar que o gateway de cobrança está sob uma pressão muito alta. Se o serviço consumidor não tiver um timeout adequado, essa lentidão se propaga para cima, degradando toda a cadeia, o cenário clássico de início de uma falha em cascata.
Comentei sobre timeout no exemplo acima, mas nem sempre ele funciona. Imagina que um serviço geralmente leva 70ms para responder, mas esse valor pode variar entre 30ms e 200ms. Como você setaria timeout nesses casos?
Uma resposta óbvia e talvez inocente, você seta para um valor acima de 180ms, mas e se o contrato com serviços e dependências for menor que 140ms? Obviamente, setar o timeout para qualquer valor acima de 180ms não é uma boa opção, uma vez que você estará passando o erro da sua dependência pro consumidor e isso viola tudo que falei até agora, principalmente sobre previsibilidade e interpretação.
Um dos caminhos aqui é utilizar um circuit-breaker. Esse padrão consiste em monitorar as chamadas que o seu serviço faz a uma dependência, rastreando quantas são bem-sucedidas e quantas falham ou excedem o timeout. Quando um determinado limite de falhas é atingido, o circuit breaker “abre”, fazendo com que o serviço assuma que a dependência está indisponível e pare de enviar requisições para ela. Isso permite que o serviço detecte a falha imediatamente e tome uma ação alternativa.
No contexto do nosso serviço de pagamentos, se o gateway de cobrança começa a falhar consistentemente, o circuit breaker abre e o serviço para de tentar processar cobranças por aquele gateway. Em vez de acumular requisições que vão dar timeout e degradar toda a cadeia, o serviço pode retornar imediatamente um erro claro como 503 Service Unavailable ou acionar um gateway alternativo, se houver (aí vai da sua arquitetura).
Periodicamente, o circuit breaker envia uma requisição de teste para a dependência, se ela voltar a responder com sucesso acima de um limite predefinido, o circuito “fecha” novamente e o serviço retoma o fluxo normal.
Uma resposta que demora a chegar de um serviço (ao invés de nunca chegar) é talvez a mais difícil de ser detectada, pois o problema começa em determinar o quão lento é lento e aqui o bicho pega por que, usando timeouts ou circuit breakers é geralmente insuficiente para lidar com a situação, porque uma resposta lenta às vezes pode ser rápida o suficiente, gerando resultados erráticos.
Vale lembrar que previsibilidade da resposta é uma característica bem importante para seu serviço e a dependência que falha de forma não previsível vai complicar a sua habilidade de criar respostas previsíveis para suas dependências. É complicado entender de início, mas depois fica fácil.
Um mecanismo de timeout mais sofisticado, combinado com circuit breaker, pode ajudar a detectar dependências lentas com mais precisão. A ideia é criar “buckets” que categorizam as chamadas recentes a uma dependência com base no tempo de resposta. Cada chamada é registrada no bucket correspondente à sua latência, e os registros são mantidos apenas por um período específico de tempo.
A partir desses buckets, você define regras em camadas para acionar o circuit breaker. No serviço de pagamentos, por exemplo:
Se 500 requisições em um minuto levam mais de 180ms para o gateway de cobrança responder, o circuit breaker abre;
Se 50 requisições em um minuto levam mais de 300ms, o circuit breaker abre;
Se 5 requisições em um minuto levam mais de 1000 ms, o circuit breaker abre.
Essa abordagem em camadas captura degradações severas mais rapidamente (bastam 5 requisições muito lentas) sem ignorar degradações mais sutis que se acumulam em volume. Uma lentidão generalizada de 180ms pode não parecer crítica em uma única requisição, mas 500 delas em um minuto indicam que algo está errado e que a cascata de falhas está prestes a começar.
Tomando ações
Beleza, agora que você já entende como falhas acontecem e como responder a elas, é hora de falar sobre as ações que o seu serviço pode tomar quando uma dependência falha.
Recomendo também a leitura desse post que escrevi em Janeiro/26 sobre Graceful Shutdown. Ele vai complementar muito bem o tema. 😉
Graceful Shutdown - Como não perder milhares de Reais em 5 minutos de deploy

Imagina o seguinte cenário: você trabalha em um e-commerce com alto volume de tráfego e logo no início do ano a diretoria comercial junto ao marketing decide realizar uma mega promoção de queima de estoque de produtos que não venderam na Black Friday, com desconto agressivo e prazo curto.
Graceful Degradation
Se uma dependência falha, o seu serviço consegue continuar operando sem a resposta dessa dependência? Consegue executar ao menos uma parte do trabalho esperado? Se sim, isso é um exemplo de Graceful Degradation, ou usando um termo em português “degradação graciosa”.
Graceful Degradation é quando um serviço reduz o mínimo possível a quantidade de trabalho que realiza diante da indisponibilidade de uma dependência.
Funcionalidade reduzida
Imagine que nosso serviço de pagamentos possui uma tela de checkout que exibe, além do formulário de cobrança, o histórico recente de compras do cliente. Esse histórico é fornecido por um serviço de pedidos. Se o serviço de pedidos falha, o que o checkout deveria fazer?
Uma opção é continuar exibindo o formulário de pagamento normalmente sem o histórico de compras, ou com uma mensagem como “não foi possível carregar suas compras recentes”.
O cliente ainda consegue concluir a compra, que é a operação crítica. O checkout continua funcionando, apenas com a capacidade reduzida de não exibir o histórico.
Isso é muito superior a derrubar toda a página de checkout e retornar um erro para o usuário simplesmente porque um componente secundário está indisponível. A cobrança é o que importa, o histórico é complementar.
Graceful Backoff
Existe um ponto em que a degradação não é mais suficiente, simplesmente não há resultados disponíveis o bastante para que a resposta seja útil. A requisição precisa falhar. Mas em vez de apenas retornar um erro, será que o seu serviço consegue realizar alguma ação alternativa que ainda entregue valor ao consumidor?
Mudar o que o serviço faz de forma a oferecer algum valor, mesmo quando não é possível completar a requisição original, é um exemplo de Graceful Backoff.
No serviço de pagamentos, imagine que o gateway principal de cobrança e o gateway secundário estão ambos fora do ar. Não há como processar o pagamento. Em vez de simplesmente retornar um 503 e deixar o cliente sem resposta, o serviço poderia registrar a intenção de compra e responder com algo como “não conseguimos processar seu pagamento agora, mas salvamos seu carrinho, você receberá um aviso assim que o pagamento puder ser concluído”. O pedido não foi finalizado, mas o cliente não perdeu a seleção de produtos, e o serviço preservou a possibilidade de conversão futura.
Falhe o Mais Rápido Possível
E quando não for possível continuar operando sem a resposta da dependência que falhou? Se não existe uma funcionalidade reduzida ou um graceful backoff que faça sentido? Sem aquela resposta, o serviço simplesmente não consegue fazer nada útil. Nesse caso, a única opção é falhar a requisição, e quando isso acontece, é fundamental falhar o mais rápido possível. Não continue executando outras etapas da requisição original depois de saber que ela vai falhar.
No serviço de pagamentos, se o serviço de antifraude está indisponível e a política da empresa exige validação de fraude antes de qualquer cobrança, não há como prosseguir. Nesse cenário, não faz sentido validar o cartão, reservar estoque ou gerar um ID de transação, tudo isso será descartado. O serviço deve retornar imediatamente um erro claro e liberar os recursos.
Aqui você pode realizar o máximo de validações possíveis logo no início da requisição. Verifique campos obrigatórios, limites de valor, formato do cartão e permissões do cliente antes de acionar qualquer dependência externa. Assim, quando o serviço avançar para as etapas mais custosas, há uma boa chance de que a requisição será concluída com sucesso, e as falhas evitáveis já foram eliminadas antes de consumir recursos desnecessários.
Agora, por que falhar cedo?
Conservar Recursos
Se uma requisição vai falhar, qualquer trabalho realizado antes de identificar essa falha é trabalho desperdiçado. No serviço de pagamentos, imagine processar uma cobrança sem antes verificar se o cliente existe. O serviço consulta o gateway de antifraude, valida o cartão, reserva estoque, e só então descobre que o ID do cliente é inválido. Todas essas chamadas para dependências externas consumiram recursos à toa, apenas para resultar em um erro.
Responsividade
Quanto antes o serviço determinar que uma requisição vai falhar, antes poderá devolver essa informação ao serviço consumidor. No serviço de pagamentos, se o valor da cobrança é negativo, rejeitar imediatamente com um 400 Bad Request permite que o consumidor corrija e reenvie a requisição em milissegundos ao invés de esperar segundos por um timeout de uma dependência que nem precisava ser acionada.
Complexidade do erro
Às vezes, permitir que uma requisição que vai falhar avance pelo fluxo só ficará mais difícil de debugar e entender onde está o problema.
No serviço de pagamentos, considere uma cobrança com valor zero. É possível detectar isso imediatamente e rejeitar a requisição. Mas se o serviço seguir adiante e enviar essa cobrança ao gateway, o comportamento pode ser imprevisível, o gateway pode retornar um erro genérico, travar em um loop de retry interno, ou até registrar uma transação fantasma que depois precisará ser conciliada manualmente.
Uma falha simples se transforma em um problema operacional muito mais difícil de resolver.
Se liga aí que é hora da revisão!
Falhas em cascata não começam com uma explosão. Elas começam com uma resposta lenta que ninguém notou, um timeout mal configurado, ou um serviço que retornou 200 OK quando deveria ter retornado um erro. O estrago acontece de forma silenciosa, dependência por dependência, até que o sistema inteiro caia e aí já é tarde demais.
A boa notícia é que a maioria dessas falhas é fácil de prevenir. Respostas previsíveis, contratos bem definidos, circuit breakers, graceful degradation e a disciplina de falhar cedo são padrões que existem há anos, o desafio é aplicá-las de forma consistente.
Novamente, construir rápido é ótimo. A AI está possibilitando isso todos os dias, mas construir rápido e de forma resiliente é o que separa um protótipo de um sistema production-ready.