
Graceful Shutdown - Como não perder milhares de Reais em 5 minutos de deploy
Um guia completo para encerrar aplicações de forma controlada


Imagina o seguinte cenário: você trabalha em um e-commerce com alto volume de tráfego e logo no início do ano a diretoria comercial junto ao marketing decide realizar uma mega promoção de queima de estoque de produtos que não venderam na Black Friday, com desconto agressivo e prazo curto.
Tudo no ar, campanhas rodando em redes sociais, tráfego subindo, todo mundo animado. Até que percebem que um cálculo errado de preço está sendo aplicado em parte do catálogo, afetando diretamente alguns dos produtos da promoção.
Não tem muito o que discutir, é preciso corrigir. A única saída é um novo deploy para sanar o problema.
Seu time faz a correção, o CI passa, o deploy começa. Minutos depois, o time de atendimento dispara no Slack dizendo que vários clientes não conseguiram finalizar compras nos últimos 5 minutos, exatamente o tempo que levou para o rollout da nova versão. Carrinhos abandonados, pagamentos falhando, reclamações públicas. Climão.
Você começa a investigar e percebe que diversas requisições simplesmente não foram concluídas durante o deploy. Algumas morreram no meio do caminho. Outras nunca receberam resposta.
O que aconteceu? Sua aplicação morreu no meio de transações ativas. Pedidos sendo processados foram abortados. Pagamentos ficaram em estados inconsistentes. Workers processando emails de confirmação morreram deixando eventos órfãos no Kafka.
E agora? Como evitar que isso aconteça de novo?
É aqui que entra o Graceful Shutdown, uma forma de encerrar uma aplicação de maneira controlada, garantindo que requisições em andamento sejam concluídas antes do processo morrer.
O que é Graceful Shutdown de verdade?
Graceful Shutdown é um contrato operacional entre sua aplicação e o ambiente onde ela roda. Para satisfazer esse contrato, você precisa garantir três coisas:
Não aceitar novas requests e workloads: Encerrar o recebimento de novas requisições HTTP; Parar de consumir mensagens de filas (Kafka, RabbitMQ, SQS); Sem derrubar conexões já estabelecidas com banco de dados ou cache;
Completar todo processamento: Aguardar que todas as requisições ativas sejam concluídas; Processar mensagens que já foram retiradas da fila; Se ultrapassar um tempo aceitável, responder com erro previsível, não timeout genérico.
Liberar recursos: Encerrar conexões com bancos de dados; Commitar offsets do Kafka; Liberar locks de arquivos; Finalizar qualquer comunicação ativa com sistemas externos.
Neste artigo, vou mostrar como implementar isso em Go, mas o conceito vale para qualquer linguagem, runtime ou plataforma de orquestração.
Como processos sabem que devem morrer?
Antes de nos aprofundarmos em Graceful Shutdown, é importante entender como processos são “avisados” de que precisam parar. Vamos voltar ao cenário do e-commerce, quando você fez o deploy, o que exatamente aconteceu do ponto de vista do processo rodando no container?
Sinais
Em sistemas Unix-like, processos são notificados através de sinais. Sinais são interrupções enviadas pelo sistema operacional (ou por outro processo) para notificar que algo relevante aconteceu e uma ação precisa ser tomada.
Quando um sinal é entregue, o fluxo normal de execução do processo é interrompido para que ele possa reagir a esse evento.
Porém, nem todo processo reage da mesma forma a um sinal, e nem todo sinal permite reação.
Existem três comportamentos possíveis:
Signal handler
Um signal handler é uma função registrada pela aplicação para lidar com um sinal específico. Quando o sinal é recebido, o processo não morre automaticamente. Em vez disso, o handler é executado, permitindo que a aplicação:
Pare de aceitar novas requisições;
Aguarde requisições em andamento;
Libere recursos;
Finalize de forma controlada.
Ação padrão (default action)
Se a aplicação não define um handler, o sistema operacional executa a ação padrão associada ao sinal e dependendo do sinal, essa ação pode ser:
Encerrar o processo imediatamente;
Ignorar o sinal;
Parar (suspender) o processo.
Unblockable signals (sinais que não podem ser tratados)
Alguns sinais não podem ser interceptados ou ignorados, independentemente do que a aplicação faça. Os mais conhecidos são SIGKILL e o SIGSTOP. Quando um desses sinais é enviado, o processo morre imediatamente, sem chance de cleanup, sem handler, sem tempo de reagir.
E em ambientes conteinerizados?
No Kubernetes, o processo normalmente recebe um SIGTERM antes de qualquer coisa mais agressiva. Esse é como se fosse um último aviso educado para a aplicação.
Se a aplicação não trata SIGTERM ou demora mais do que o tempo configurado, o orquestrador envia um SIGKILL e a sua aplicação cai.
Voltando ao cenário do deploy com bug de preço
15:29:58 - Deploy iniciado
15:30:00 - Kubernetes envia SIGTERM para Pod antigo
15:30:00 - Sua aplicação IGNORA o sinal (não tem handler)
15:30:00 - Runtime do Go encerra processo imediatamente
15:30:00 - 47 requisições HTTP ativas abortadas
15:30:00 - 12 mensagens Kafka meio processadas
15:30:00 - 3 workers gerando relatórios mortos
15:30:01 - Time de atendimento começa a receber reclamaçõesO erro comum
Muitos times acham que “Graceful Shutdown é coisa do Kubernetes” ou do load balancer, a real é que não é.
O Graceful Shutdown começa dentro da aplicação, no momento em que ela decide o que fazer ao receber um sinal.
Lidando com sinais em Go
Quando uma aplicação Go inicia, antes mesmo da função main rodar, o runtime registra handlers para vários sinais do sistema operacional. Esses handlers existem para garantir que o processo termine de forma previsível.
Porém, para Graceful Shutdown, quase tudo é ruído. Na prática, três sinais concentram 99% dos cenários reais:
SIGTERM: Indica que o processo deve encerrar. É o sinal enviado por orquestradores como Kubernetes durante deploys, scale down ou evictions. Ele pode e deve ser tratado pela aplicação;SIGINT: Normalmente enviado quando alguém pressionaCtrl+Cno terminal. O comportamento esperado é encerrar de forma limpa, assim como noSIGTERM;SIGHUP: Historicamente é um sinal utilizado para indicar fechamento de terminal. Hoje em dia, ele costuma ser usado para recarregar configs.
Por padrão, ao receber qualquer um desses sinais, o runtime do Go encerra o processo imediatamente. Isso significa que:
Requisições em andamento são abortadas;
Conexões são fechadas sem aviso;
O sistema externo que chamou sua aplicação não vai receber a resposta.
Para mudar esse comportamento, é necessário interceptar os sinais usando o pacote os/signal.
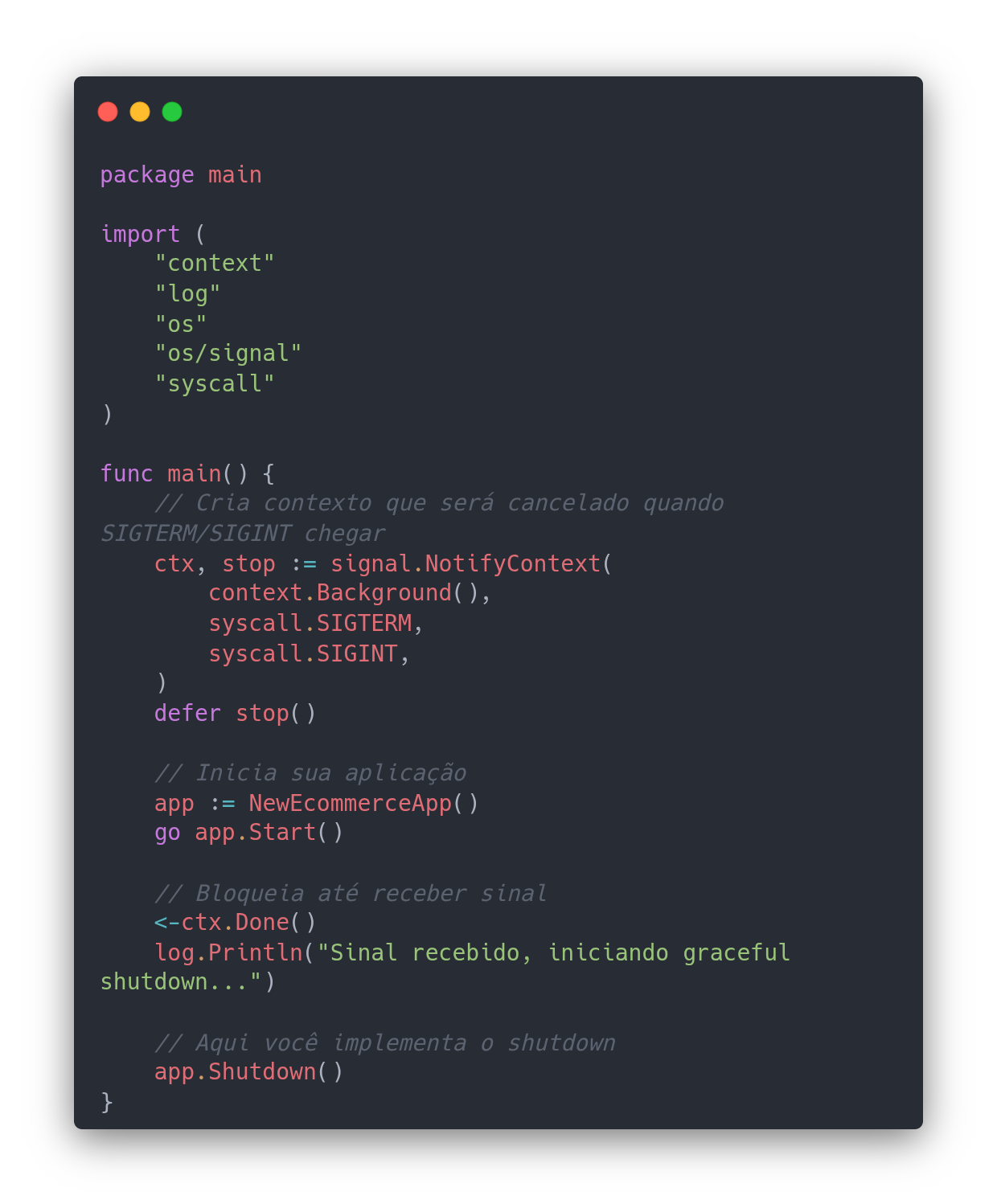
Basicamente, signal.NotifyContext (disponível desde o Go 1.16) faz com que o runtime notifique os sinais para um contexto ao invés de executar o comportamento padrão, permitindo que você configure a melhor forma de prevenir que a aplicação termine de forma abrupta.
Timeout não é detalhe
Graceful Shutdown não acontece no seu tempo, acontece no tempo que o ambiente permite.
Quando sua aplicação recebe um sinal de encerramento, existe um relógio invisível rodando. Se ele zerar antes do seu cleanup terminar, o sistema simplesmente mata o processo.
No Kubernetes, por exemplo, o comportamento padrão é o seguinte:
Ao iniciar um deploy, scale down ou eviction, o Pod recebe um
SIGTERM;A partir desse momento, começa a contar o valor que é especificado no
terminationGracePeriodSeconds, que por padrão são 30 segundos - doc;Se o processo ainda estiver vivo ao final desse período, o Kubernetes envia um
SIGKILL.
E aqui não tem negociação, o SIGKILL não pode ser interceptado, tratado ou ignorado. O processo morre imediatamente, no estado em que estiver.
Isso significa que toda a sua lógica de shutdown precisa caber dentro dessa janela:
Concluindo requisições em andamento;
Respondendo erros controlados se necessário;
Liberando conexões;
Finalizar goroutines e workers.
No cenário do e-commerce, se você tem:
Requisições HTTP de checkout que levam 5-8 segundos (validação de estoque, pagamento, nota fiscal);
Workers processando emissão de Notas Fiscais que levam 10-15 segundos;
Consumidor Kafka commitando offsets em batch a cada 30 segundos.
Você tem um baita de um problema. O shutdown padrão de 30s não vai dar conta.
Parando de receber requisições: HTTP Server
Vamos começar pelo básico, fazer o servidor HTTP parar de aceitar novas requisições.
O pacote net/http possui o método http.Server.Shutdown(ctx) que implementa Graceful Shutdown nativamente. Ele para de aceitar novas conexões, aguarda as requisições em andamento completarem (respeitando o contexto passado) e então fecha as conexões idle. Veja um exemplo aqui.
Se você usa Gin, ele não possui método próprio, você usa o http.Server.Shutdown diretamente, já que Gin é apenas um wrapper em cima do net/http. Exemplo aqui.
Já se você usa o Fiber (minha escolha pessoal), ele tem seu próprio método, o app.ShutdownWithContext(ctx) porque usa o fasthttp por baixo e não o net/http. Exemplo.
Comportamento comum aos três
Independte da implemente, framework, o comportamento é o mesmo:
Param de aceitar novas conexões imediatamente;
Aguardam requisições ativas finalizarem (com timeout do contexto);
Fecham conexões idle;
Porém, não garantem que requisições vão completar se o timeout do contexto expirar.
O problema do Kubernetes
Já no Kubernetes, mesmo após o Pod ser marcado para termination, o kube-proxy pode demorar alguns segundos (~5-10s) para atualizar as regras de iptables e remover o Pod dos endpoints do Service.
Durante essa janela, você ainda pode receber tráfego. O que acontece:
15:30:00 - SIGTERM enviado
15:30:00 - app.Shutdown() chamado imediatamente
15:30:00 - Servidor para de aceitar conexões
15:30:01 - Cliente tenta conectar → Connection refused
15:30:02 - Cliente tenta conectar → Connection refused
15:30:05 - kube-proxy finalmente atualiza iptables
15:30:05 - Agora sim, tráfego para de chegarO resultado são clientes recebendo erros 5xx.
Uma boa solução é implementar um delay antes de chamar o Shutdown:
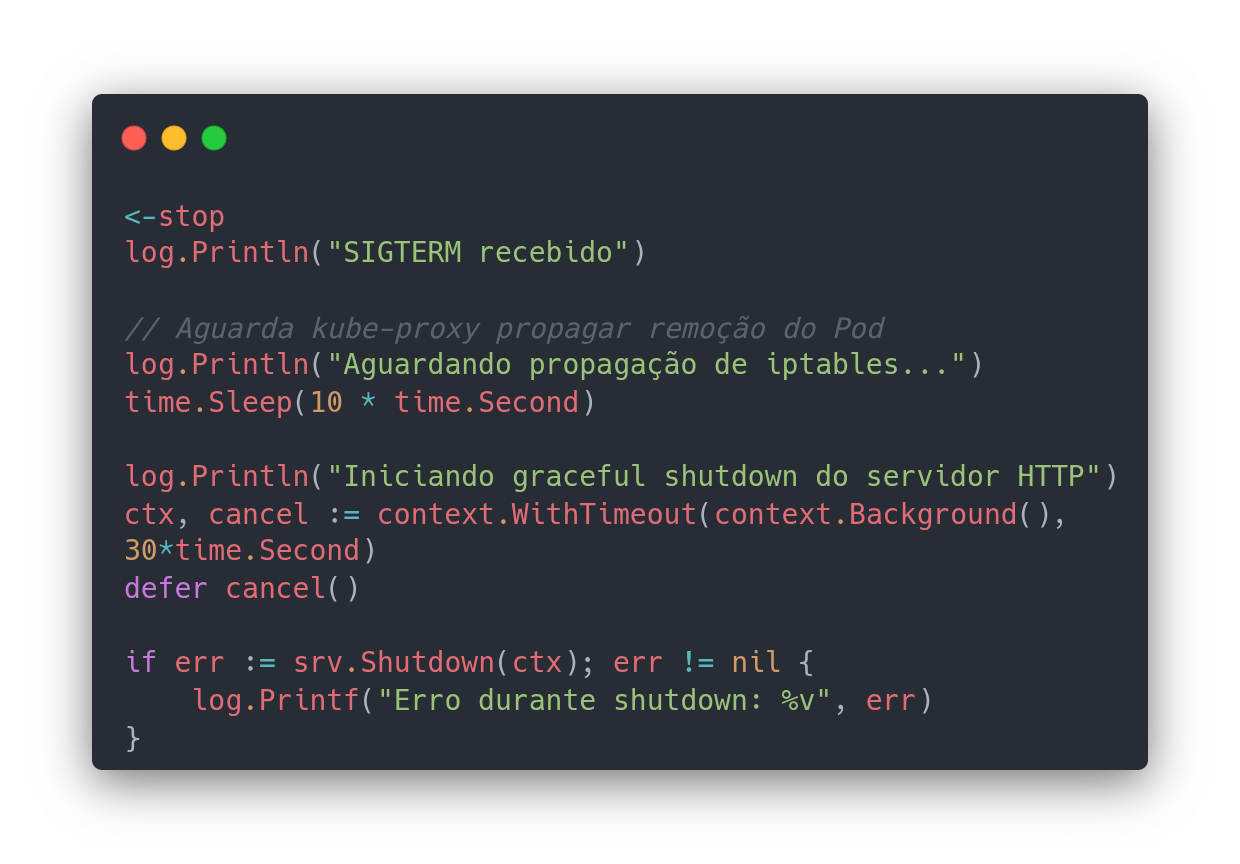
E agora o fluxo ficaria algo assim:
15:30:00 - SIGTERM recebido
15:30:00 - Aplicação aguarda 10s (delay intencional)
15:30:05 - kube-proxy atualiza iptables
15:30:10 - app.Shutdown() chamado
15:30:10 - Servidor para de aceitar conexões (mas não chega mais tráfego)
15:30:12 - Requisições ativas completadas
15:30:12 - Servidor encerrado O que você esqueceu de desligar
Você implementou http.Server.Shutdown, testou localmente, fez deploy em produção. Tudo funcionando. Até que numa terça-feira às 3 da manhã você recebe um alerta: mensagens duplicadas no Kafka, jobs incompletos no banco, relatórios corrompidos.
O que aconteceu? Seu servidor HTTP morreu corretamente com Graceful Shutdown, mas o resto da aplicação morreu no meio do caminho.
O problema real
Aplicações não são só servidores HTTP. Elas têm:
Consumidores de fila processando eventos assíncronos;
Workers em background gerando relatórios, enviando emails, processando uploads;
Jobs agendados fazendo limpeza, sincronização, cálculos periódicos;
Conexões persistentes com bancos, caches, message brokers.
Quando você faz Graceful Shutdown apenas do servidor HTTP, esses componentes continuam rodando até o SIGKILL chegar (~30s depois no Kubernetes). O resultado:
15:30:00 - SIGTERM recebido
15:30:00 - HTTP server para de aceitar requests
15:30:02 - HTTP server finaliza últimas requisições
15:30:02 - HTTP server encerrado
15:30:02 - Kafka consumer ainda processando pedido #8472
↳ Validando estoque, reservando produtos...
15:30:15 - Worker ainda gerando nota fiscal do pedido #8480
↳ PDF 70% completo, gravando no S3...
15:30:20 - Job de sincronização com ERP ainda rodando
↳ Atualizando 4.823 produtos de 10.000...
15:30:30 - SIGKILL → tudo morre abruptamente
↳ Pedido #8472: estoque reservado mas não commitado no Kafka
↳ Nota fiscal #8480: PDF corrompido no S3
↳ Sincronização ERP: estado inconsistenteA sequência de shutdown também é importante. Você precisa respeitar as dependências entre componentes:
Fase 1
Primeiro você impede que novos processamentos ocorram no sistema:
HTTP Server para de aceitar requisições;
Kafka Consumer para de consumir novos eventos;
Jobs agendados devem ser cancelados.
A ideia de fazer nessa ordem é porque o servidor HTTP pode enfileirar eventos no Kafka, e o Kafka pode disparar jobs. Se você parar o Kafka antes do HTTP, requisições vão falhar ao tentar publicar os eventos.
Fase 2
Aqui a ideia é finalizar todo processamento que está em andamento:
Requisições HTTP ativas, por exemplo: checkout, pagamento;
Kafka Consumers: Finaliza processamento, commita offsets;
Workers: Completa geração de Notas Fiscais, envio de e-mails;
Jobs: Termina sincronização com ERP.
Fase 3
Por fim, você a aplicação deve liberar conexões com recursos externos:
Fecha conexões com o Kafka, tanto de producer quanto consumer;
Encerra conexão com o banco de dados;
Encerra conexão com o Redis, memcached ou qualquer outro sistema de cache;
Libera locks de arquivos.
Essa ordem importa, por que se você fechar a conexão com o banco de dados enquanto os workers ainda estão salvando Notas Fiscais, você verá um connection closed do nada. Se fechar a conexão com o Kafka antes de commitar os offsets, vai ter que reprocessar mensagens.
Exemplo:

Goroutines também precisam saber a hora de morrer
Outro ponto ignorado com frequência: goroutines não morrem sozinhas.
Quando o processo recebe um SIGTERM:
O runtime não cancela goroutines automaticamente;
Loops infinitos continuam rodando;
Workers bloqueados continuam bloqueados.
Se você não tem um mecanismo claro de cancelamento (normalmente via context.Context), você está acreditando que o processo vai morrer rápido o suficiente, ou o orquestrador vai mandar SIGKILL.
Nenhuma das duas opções é uma boa estratégia.
Uma boa aqui é utilizar context-aware goroutine, exemplo. Agora caso você tem várias goroutines, use sync.WaitGroup para aguardar todas finalizarem, exemplo.
Toda goroutine de longa duração deveria responder a cancelamento. Se ela não sabe quando parar, ela é provavelmente é um leak.
Shutdown precisa ser previsível, não best effort
Muita gente implementa shutdown como algo “best effort”, tenta fechar tudo e torce para dar tempo e isso é frágil.
O shutdown precisa ter:
Ordem clara, o que encerra antes do quê;
Limites de tempo explícitos;
Lembra das fases que citei acima?
Fallback bem definido. O que acontece se algo não for encerrado conforme esperado?
Esses tempos precisam ser mensurados e testados. Uma dica aqui é adicionar uma gordura. Voltando ao nosso cenário:

Vamos relembrar que o terminationGracePeriodSeconds por padrão no Kubernetes são 30 segundos, mas a soma das nossas fases dá ~35s. Isso é intencional, você quer que todas fases termine antes do SIGKILL.
Você pode muito bem configurar o lifecycle do seu Deployment/Pod através do parâmetro terminationGracePeriodSeconds e utilizar o preStop hook.
Observe o shutdown como um evento crítico
Outro erro recorrente, o shutdown não é observado.
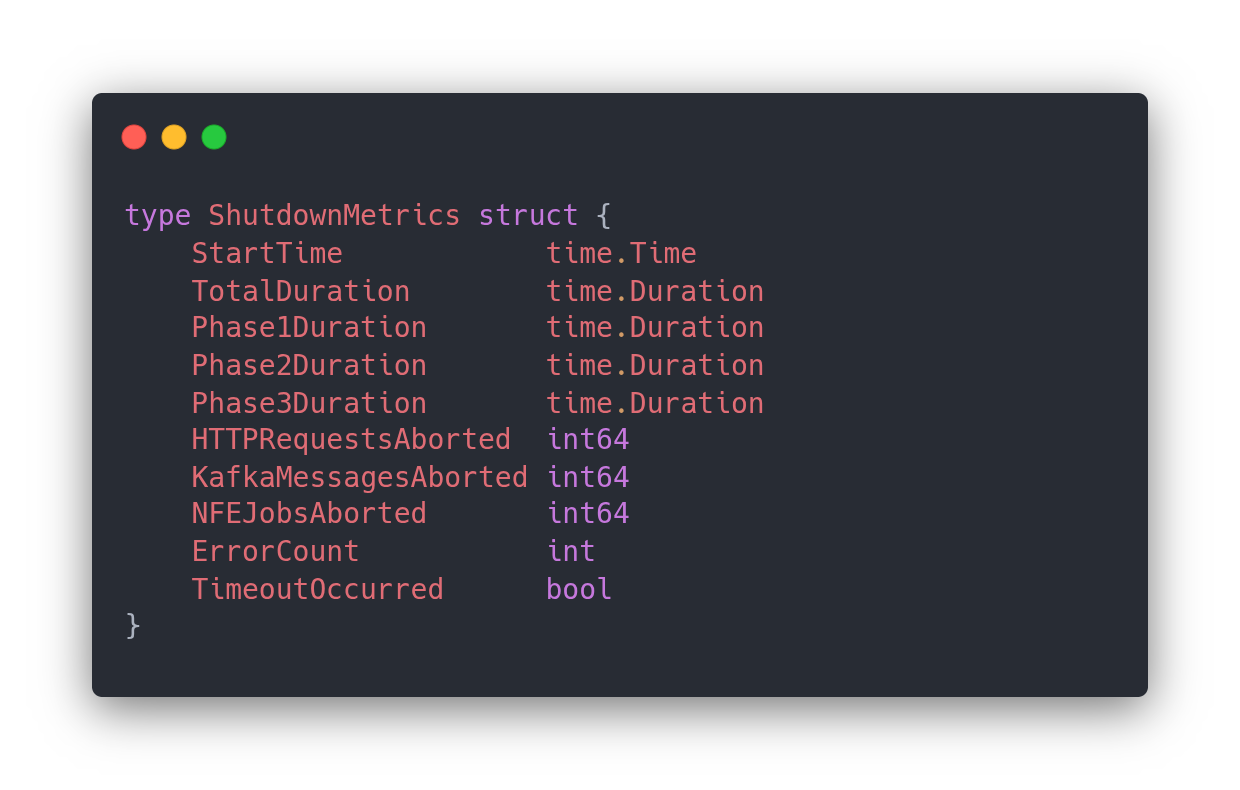
Em produção, você deveria conseguir responder:
Quanto tempo o shutdown levou?
Q que demorou mais?
Quantas requisições foram abortadas?
Houve timeout?
Sem logs claros e métricas, o shutdown vira um buraco negro. Quando algo dá errado, ninguém sabe o real motivo.
Talvez esse seja o grande ponto de reflexão do meu post, Graceful Shutdown é um evento operacional importante, não um detalhe de implementação.
Dicas para mensurar
Através métricas para mensurar o tempo de duração do shutdown;;
Através de logs contendo duração, quantas requests estavam ativas, quantos jobs estavam pendentes;
Crie uma dashboard para monitorar esses tempos, com duração do shutdown, quantos shutdowns foram bem sucedidos, a duração por fase e quantas requests foram abortadas;
Alerte apenas em casos críticos. Quando o shutdown está próximo dos 30s ou do valor que você definir do
terminationGracePeriodSeconds.
Não teste só quando dá problema
Shutdown precisa ser testado:
Localmente durante desenvolvimento;
Em staging antes de subir pra produção;
Sob carga com tráfego real;
Com latência que possa simular dependências lentas;
Com dependências como banco de dados e Kafka falhando.
Quanto antes você falhar, mais barato é corrigir.
Conclusão
Graceful Shutdown não é uma feature opcional nem um detalhe de infraestrutura.
Ele é parte do contrato da aplicação com o ambiente onde ela roda.
Se você ignora:
Sinais do sistema operacional;
Limites de tempo impostos pelo orquestrador;
Requisições em andamento;
Goroutines e workers;
O sistema vai continuar funcionando, até o dia em que o deploy custar dinheiro, reputação ou ambos.
Próximos passos
Se você ainda não tem Graceful Shutdown:
Comece pelo básico interceptando
SIGTERMeSIGINT;Implemente shutdown do servidor HTTP;
Identifique todos os componentes concorrentes (Kafka, workers, jobs);
Implemente shutdown coordenado respeitando dependências;
Adicione logs e métricas;
Teste localmente com
Ctrl+C;Teste em staging sob carga;
Faça rollout gradual em produção;
Monitore e ajuste timeouts baseado em dados reais.
Se você já tem Graceful Shutdown:
Revise a ordem, ela respeita dependências?;
Meça os timeouts;
Adicione observabilidade;
Teste sob condições adversas;
Configure alertas;
Documente.
Fiquem a vontade para comentar suas soluções, como vocês implementam ou se possuem dúvidas sobre o tema.
Até mais!