
Mensurando e Entendendo Disponibilidade
Entenda como medir e melhorar a disponibilidade de sistemas para garantir experiências confiáveis aos clientes. Descubra a relação entre resiliência, métricas e estratégias para evitar downtime.


Um dos pontos mais importantes ao arquitetar sistemas escaláveis é disponibilidade. Existem serviços que um certo tempo de downtime é entendível e até esperado e alguns não podem ficar fora do ar de forma alguma.
Acredito que existem perguntas essenciais que não só times de engenharia, mas também times de negócio e produto devem se fazer ao determinar o quão importante é a disponibilidade de sistemas para a empresa e para seus clientes. Como por exemplo:
Por que comprar seu produto? Por que alguém compraria seu produto ou seu serviço se ele não está operacional ou acessível quando eles precisam?
O que os clientes pensariam nesse cenário? O que eles pensariam ou sentiriam sobre a marca/empresa quando eles precisam usar seu serviço e ele está fora do ar?
Qual é o nível de satisfação dos seus clientes? Como você pode fazer os clientes felizes, trazer dinheiro para a empresa e atender as promessas do seu negócio se os serviços estão fora?
E a real é que a respostas para essas perguntas levam a um único ponto. Seu sistema precisa estar operacional. Existe uma relação direta entre nível de satisfação de seus clientes com a disponibilidade de seus serviços.
Disponibilidade e Resiliência
Disponibilidade e resiliência são dois conceitos muito similares, porém diferentes e é importante entender essa diferença. Ainda mais se você trabalha com SRE ou arquitetando e desenvolvendo aplicações.
Disponibilidade se refere a habilidade de um sistema em realizar suas operações. Se o sistema está de pé, está operacional e está respondendo então sim, ele está disponível.
Já resiliência se refere a qualidade do sistema, se o sistema consegue de forma consistente realizar suas operações.
Novamente, ambos conceitos são super parecidos. É difícil um sistema ser disponível se ele não é resiliente e o contrário também é uma verdade.
Se um sistema que recebe dois parâmetros e os soma, por exemplo “4” e “2” e retorna “8”, ele tem uma baixa resiliência. Nesse cenário, a resiliência pode ser corrigida ao implementar testes. Já a disponibilidade é mais difícil de se resolver. Vamos a mais um cenário, imagine que o sistema ao receber os mesmos parâmetros retorne “6”, ele é resiliente. Mas devido a um problema de rede, as vezes ele retorna 6, as vezes não retorna nada. A aplicação é resiliente, mas não é sempre disponível.
Causas de Disponibilidade Degradada
Exaustão de recursos: Quando a quantidade de usuários ou a quantidade de dados trafegados ou armazenados aumenta resultando em requisições lentas;
Mudanças inesperadas na carga que o sistema suporta: Geralmente requer mudanças de última hora e sem planejamento, tanto na infraestrutura quanto no código e podem aumentar a probabilidade de mais problemas;
Dependências externas: Quanto mais seu sistema depender de recursos externos, como SaaS, mais o seu sistema estará exposto a problemas de disponibilidade causado por esses recursos;
Dívida técnica: Quanto mais as aplicações se tornam complexas, geralmente, a dívida técnica cresce junto e dívida técnica é sinônimo de problema em algum momento.
O ponto aqui é que problemas de disponibilidade custam dinheiro para você, para seus clientes e afeta diretamente a confiança dos clientes no negócio e produto. Provavelmente a empresa não vai pra frente se você tem problemas constantes de disponibilidade e contruir aplicações que precisam escalar é construir aplicações que tenham alta disponibilidade.
Medindo Disponibilidade
Medir a disponibilidade é importante para manter seu sistema sempre operacional. Ao mensurá-la você pode entender como sua aplicação está performando agora e compará-la daqui 1 semana, 1 mês ou sempre que uma nova funcionalidade nova for para produção.
O mecanismo mais utilizado para medir a disponibilidade é calcular a porcentagem de quanto aquele sistema está disponível para os clientes, onde pode ser utilizada a seguinte fórmula:
Exemplo, durante o mês de Janeiro, seu sistema ficou fora do ar 3 vezes, a primeira 40 minutos, a segunda 20 minutos e a terceira 5 minutos. Qual seria a disponibilidade desse sistema?
Segundos fora do ar: (40*60)+(20*60)+(5*60) = 3.900s
Segundos em um mês: 31 dias x 86.400s/dia = 2.678.400s
Agora aplicando a fórmula:
A disponibilidade seria ~99.8%. O que nos leva ao próximo tópico e uma pergunta que ouvimos bastante, “a disponibilidade da sua aplicação está em quantos noves?”
Os Noves
Estamos acostumados a relacionar “os noves” como indicadores de alta disponibilidade. A tabela abaixo dá uma visão geral do que isso significa.
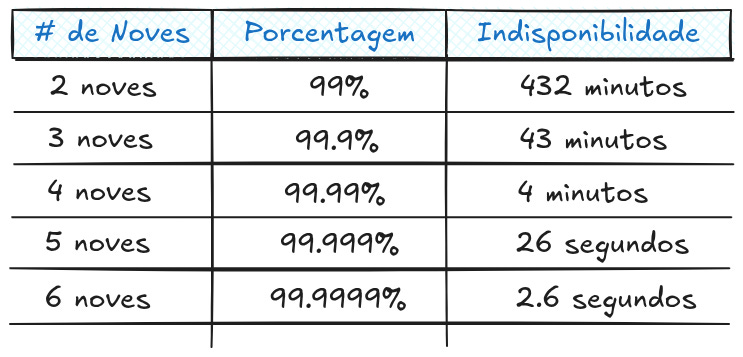
Um sistema que tem 2 noves de disponibilidade, precisa estar disponível 99% do tempo, ou seja, o sistema pode ficar fora 432 minutos por mês. Já uma aplicação que garante 5 noves de disponibilidade pode ter apenas 4 minutos de downtime por mês.
No exemplo que mostrei anteriormente, a aplicação falhou em atender a disponibilidade de 3 noves (99.8% comparado a 99.9%). Mas qual é o valor razoável para seu sistema ser considerado como altamente disponível? E a resposta para isso é, depende. Você vai precisar determinar isso com negócio/produto da sua empresa e nesse momento você precisa saber ouvir e saber vender qual seria o trabalho (e custo) necessário pra chegar no nível desejado. O ideal é chegar ao meio termo. Geralmente para aplicações web 3 noves é considerado como aceitável.
Vale lembrar que manutenções programadas também são consideradas como downtime. Vamos aplicar a mesma fórmula anterior em um cenário onde o time realiza manutenções preventivas toda semana e o sistema fica fora por 3 horas.
Horas em uma semana: 7 x 24 horas = 168 horas
Horas indisponíveis por semana: 3 horas
Nesse cenário, o sistema teria disponibilidade aproximada de 98.21%, ou seja, não atinge nem 99% de disponibilidade. Isso sem contar se houver algum downtime durante o período, então por esse motivo, cuidado com manutenções planejadas.
Melhorando a Disponibilidade
Vamos para mais um cenário. Seu serviço recém lançado está operacional, está online, o time opera normalmente e tudo parece bem. O tráfego aumenta gradativamente, seu serviço é rentável e está tudo bem. Até que o sistema tem um downtime inesperado, mas tudo bem, a disponibilidade continua boa.
Até que acontece novamente e ninguém liga, pois os números continuam bons. E acontece novamente. O time de negócio começa a se preocupar, começam a pipocar tickets e reclamações para o time de atendimento e novamente, outro incidente.
Manter seu sistema disponível é uma tarefa difícil, o que você faria se isso começasse a acontecer e você precisa trabalhar para manter os clientes satisfeitos e o dinheiro entrando novamente?
Identificar cenários como esse são essenciais para evitar um ciclo vicioso de problemas e você pode ter algumas iniciativas para contornar isso:
Medir e acompanhar a disponibilidade geral;
Automatizar processos manuais;
Automatizar processos de deploy;
Manter todas as configurações dos sistemas de forma centralizada;
Continuar trabalhando em melhorar seus sistemas. Isso não significa migrar para o Kubernetes, e sim identificar problemas de arquitetura, código ou infraestrutura.
Vamos nos aprofundar em cada uma delas:
Medir e acompanhar a disponibilidade geral
Para entender o que está acontecendo com a disponibilidade do sistema, você precisa medi-la primeiro e saber qual é o valor atual. Expliquei isso mais acima. Utilize a fórmula e alguma ferramenta para acomapanhar se a disponibilidade está melhorando ou piorando.
Monitore de forma contínua essa porcentagem e também quando houve alterações significativas ou não no sistema. Dessa forma você pode correlacionar eventos com incidentes.
Automatizar processos manuais
Elimine variáveis e processos desconhecidos. Realizar operações manuais é um modo comum de inserir resultados variáveis ou desconhecidos no sistema.
A dica de ouro é nunca realize operações manuais em produção.
Quando você realiza uma mudança, essa mudança pode melhorar ou comprometer de vez seu sistema. Ao usar apenas tarefas automatizadas e que podem ser repetidas traz benefícios como:
Você pode testar um processo ou script antes de executá-lo;
Realizar ajustes nesse script para executar exatamente o que você precisa;
O script pode ser revisado por um colega, com isso diminui a probabilidade de algo estar passando despercebido;
Você pode versionar scripts afim de entender quando o script foi alterado e por quem;
Possibilidade de rodar o mesmo script em vários servidores ao mesmo tempo;
Ao automatizar você cria tarefas repetitíveis e toda tarefa repetitível podem ser auditada e analisada. Ou seja, você terá como saber qual foi o impacto. Se positivo ou negativo.
Existem empresas onde ninguém tem acesso ao ambiente de produção. Toda e qualquer mudança só deve ser feita através de processos automatizados.
Deploys automatizados
Essa pode parecer mais do mesmo, mas muitas empresas ainda não tem um processo de deploy automatizado, onde a pipeline (testes, processos de segurança, build) é igual para toda e qualquer nova release.
Os processos de rollbacks também são mais confiáveis quando automatizados.
Gestão de configuração
Assim como o ponto de cima, pode parecer super comum, mas não é.
Utilizar sistemas de gestão de configuração como Ansible ao invés de sair mudando manualmente aquela variável no Kernel de um servidor é um passo bem importante. Se o Ansible é muito para seu cenário, escreva um script que faça as alterações e versione.
Para infraestrutura, utilize soluções de Infra as Code como Terraform ou Pulumi. Falo mais sobre isso aqui.
Melhorando sistemas
Agora que você tem um sistema onde é possível monitorar a disponibilidade, uma maneira de rastrear riscos e uma maneira de aplicar alterações consistentes ao seu sistema de forma fácil e segura, você pode concentrar seus esforços em melhorar a disponibilidade dele. Vou dar alguns exemplos que podem te direcionar.
Construa pensando em falhas
Planeje e desenhe as aplicações pensando que em algum momento elas vão falhar. Ou por um problema de rede, ou por um serviço terceiro fora do ar, ou por DNS :). Isso é fato, em algum momento haverão falhas, ponto. Portanto:
Quais design patterns você considerou ou utiliza que irá melhorar a disponibilidade da aplicação? Ao usar patterns simples como lógica de retry e circuit breakers você consegue identificar problemas mesmo que eles afetem apenas uma pequena funcionalidade. Isso ajuda a limitar o escopo de um problema e permite que a aplicação continue operacional em partes;
O que você faz quando um componente que a aplicação depende começa a falhar? Como você faz a retentativa da requisição? Circuit breakers são ótimos para esses casos, pois eles reduzem o impacto de falhas em dependências. Sem um circuit breaker, você diminui a performance da aplicação, principalmente quando timeouts longos são necessários para detectar uma falha;
O que você faz quando acontece um tráfego inesperado para seu sistema? O sistema cai? Você consegue limitar a quantidade de requisições?
Sempre se pergunte “isso escala?”
Não é porque sua aplicação funciona hoje que ela vai funcionar amanhã, ainda mais aplicações web, onde o tráfego de hoje pode ser totalmente diferente daqui uma semana, as vezes em até menos tempo. Construa pensando sempre no futuro:
Arquitete pensando em como escalar seus bancos de dados;
Pense nos limites lógicos ao escalar a camada de dados. O que acontece se seu banco de dados alcançar algumas de suas capacidades e limites?
Construa sua aplicação de forma que seja fácil adicionar novos servidores em caso. Como você mantém o estado da aplicação? Como o tráfego externo chega nos servidores? Existe um load balancer?
Utilize CDNs para conteúdos estáticos para minimizar o tráfego para sua rede e servidores;
Pense em quais conteúdos dinâmicos podem ser gerados de forma estática.
Mitigue riscos
Identifique possíveis riscos que seu sistema pode ter. Geralmente as causas das falhas poderiam ter sido identificadas antes delas terem ocorrido. Alguns exemplos:
Um servidor vai cair;
Os dados no banco de dados podem se corromper;
A resposta de uma requisição pode retornar errada;
Uma conexão de rede vai falhar;
Manter sistemas disponíveis envolve remover ou reduzir os riscos, mas com o aumento da complexidade isso se torna cada vez mais difícil. Manter um sistema grande disponível é muito mais sobre gerenciar seus riscos, o quanto é aceitável e o que você pode fazer para mitigá-los.
Observabilidade
Você não saberá que há um problema a menos que você o veja. Instrumente seu sistema de ponta a ponta para ter uma visão do todo. Também falei sobre isso aqui. Existem soluções Open Source que podem ser adotadas de forma fácil para essa finalidade.
O segredo é não criar um caminhão de alertas, setar SLIs e monitorar SLOs. Observe tendências na performance e os outliers (valores fora do normal) poderão ser tratados como problemas de disponibilidade, podendo dessa forma gerar alertas em ocorrências.
Resposta a incidentes
Ter um sistema observável é inútil se você não tem uma forma de atuar quando os incidentes acontecem. Estabeleça processos e procedimentos, os famosos Runbooks, que os times possam seguir para identificar problemas e corrigi-los de forma fácil.
Por exemplo, se um serviço é afetado, você deve ter uma série de passos para restaurá-lo a normalidade. Não importa se seja um restart de um daemon, de um conteiner, verificação de espaço em um banco de dados ou consumer lag de um tópico do Kafka. O importante é ter o passo a passo documentado para ajudar as pessoas a identificar o problema.
Quando um alerta é enviado, os donos dos serviços devem ser os primeiros a receber a notificação, porém, outros times que consomem ou tem algum tipo de “conexão” com o serviço afetado também podem ser notificados. Isso vai depender de cada empresa e cultura.
Outro ponto importante é documentar o escopo de atuação de cada time, ou seja, quem são os donos de determinados serviços, vamos considerar squads de um e-commerce:
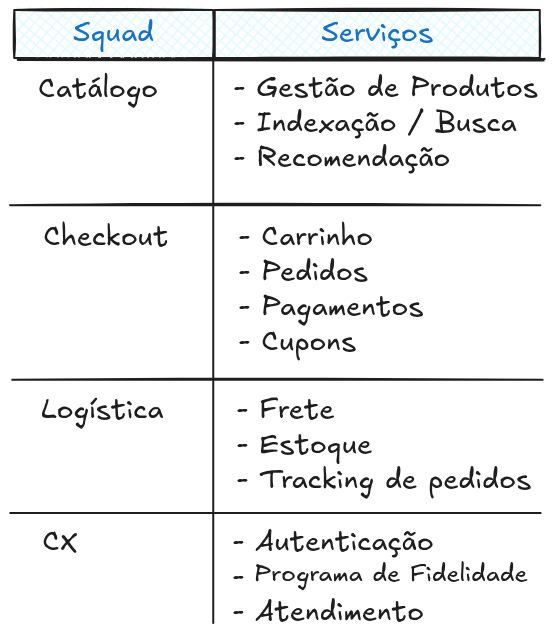
Nesse caso, a squad de Checkout é “dependente” de serviços da squad de Catálogo onde por exemplo, o carrinho não exibe o valor correto de um produto se o serviço de gestão de produtos que determina o valor está incosistente. Assim como ela também depende do serviço de cálculo de frete, do time de Logística. Criar SLOs para observar o error budget de fluxos importantes é essencial nesse cenário.
Todos esses processos e procedimentos devem ser preparados com antecedência para que, durante um incidente, os times saibam o que fazer nas diversas circunstâncias para restaurar as operações rapidamente.
Finalizando
Esse foi o primeiro post de uma série sobre boas práticas de como manter a disponibilidade com resiliência em aplicações. Nos próximos, a ideia é aprofundar mais em como lidar com falhas de forma inteligente, graceful shutdown e tudo que está em torno disso.