
Systems Performance - eBPF
Uma breve introdução sobre eBPF e como sistemas de segurança e observabilidade estão evoluindo graças a ele.


O eBPF (Extended Berkeley Packet Filter) surgiu como uma tecnologia revolucionária para observabilidade e otimização de desempenho em sistemas modernos, permitindo a execução segura de código diretamente no kernel do Linux, oferecendo uma abordagem “sandboxed” para interagir com aplicações, redes e subsistemas do hardware.
A ideia desse post é abordar alguns princípios e fundamentos mais básicos, já que o eBPF continua em constante evolução e é aplicado em cada vez mais cenários.
O que é eBPF?
O eBPF foi inicialmente desenvolvido para Linux, porém não há motivos para que ele não possa ser utilizado em outros Sistemas Operacionais. Inclusive, a Microsoft tem desenvolvido uma implementação dele para Windows.
A ideia do eBPF nasceu no início dos anos 90 como uma “pseudo máquina” que podia rodar programas como se fossem filtros, onde era determinado se um pacote de rede poderia ser aceito ou rejeitado. Esses programas eram escritos em instruções chamadas BPF (BSD Packet Filter) bem similares ao Assembly. Caso você queira se aprofundar nas raízes do eBPF, sugiro dar uma lida no paper escrito no fim de 1992 por Steven McCanne e Van Jacobson. Abaixo, um exemplo de código retirado direto desse paper:

Esse código basicamente filtra pacotes que não são pacotes IP da seguinte maneira:
O código trabalha com pacotes Ethernet como entrada;
Utilizando uma instrução
ldh, ele carrega um valor de 2 bytes a partir do byte 12 do pacote (este é o campo EtherType nos quadros Ethernet que identifica o protocolo);Uma instrução
jeqentão compara este valor com o código padrão para pacotes IP;Se houver uma correspondência, a execução salta para um “rótulo” (ou função) chamado
L1e retorna um valor não zero (#TRUE), aceitando o pacote;Se não houver correspondência, o pacote é rejeitado retornando
0.
No paper existem trechos de código bem mais complexos, porém o mais importante disso tudo é ficar claro, que a pessoa podia escrever essas instruções e serem executadas diretamente dentro do Kernel, o que possibilita a utilização do eBPF hoje em dia. A primeira utilização do BPF no Linux foi a partir da versão 2.1, no utilitário tcpdump para capturar pacotes TCP.
O BPF se tornou o que conhecemos hoje por eBPF na versão 3.18 do kernel do Linux trazendo mudanças significativas como:
Um melhor suporte a arquitetura 64-bit;
Possibilidade de criar estruturas de dados através de
maps;A syscall
bpf()foi adicionada para que programas rodando a nível de usuário pudessem interagir com programas eBPF rodando no kernel.
eBPF e o Kernel do Linux
Desde 2005 existe uma funcionalidade no kernel do Linux chamada kprobes (kernel probes), que permite que você injete “traps” em quase todas instruções de código do kernel de uma forma que novos módulos (kernel modules) possam “attachar” suas funções a esses kprobes com intuito de medir performance ou debugar aplicações.
Porém, só em 2015 foi adicionada a funcionalidade de “attachar” programas eBPF aos kprobes e foi a partir de então que a forma como todo tracing dentro de um sistema Linux começou a mudar, permitindo uma melhor visualização e entendimento de toda stack de rede daquele sistema. Nos anos seguintes, a adoção do eBPF se tornou proeminente em empresas como Netflix e Facebook possibilitando o nascimento do projeto Cilium.
Em meados de 2018, a comunidade viu o eBPF se tornar um subsistema totalmente separado dentro do kernel do Linux, a introdução do BTF, tornando programas eBPF mais portáteis e o LSM BPF, que tornou programas eBPF a serem utilizados juntos de uma interface do kernel chamada Linux Security Module (LSM), possibilitando que o eBPF fosse a melhor tecnologia para segurança, observabilidade e redes.
Kernel e o User space
Para realmente entender o eBPF, é necessário saber a diferença entre o kernel e o user space no Linux, então vamos lá.
De modo bem simples e direto, o kernel do Linux é um software que atua entre as aplicações e o hardware do sistema onde ele roda. Já as aplicações rodam em uma camada “superior” chamada user space, o que não dá acesso direto ao hardware, para isso, a aplicação que necessita ler e escrever arquivos, trafegar dados pela rede ou acessar a memória RAM, precisa fazer requests utilizando syscalls para que o kernel atue pela aplicação nesses momentos. O kernel também é responsável por coordenar processos concorrentes, permitindo que várias aplicações rodem ao mesmo tempo.
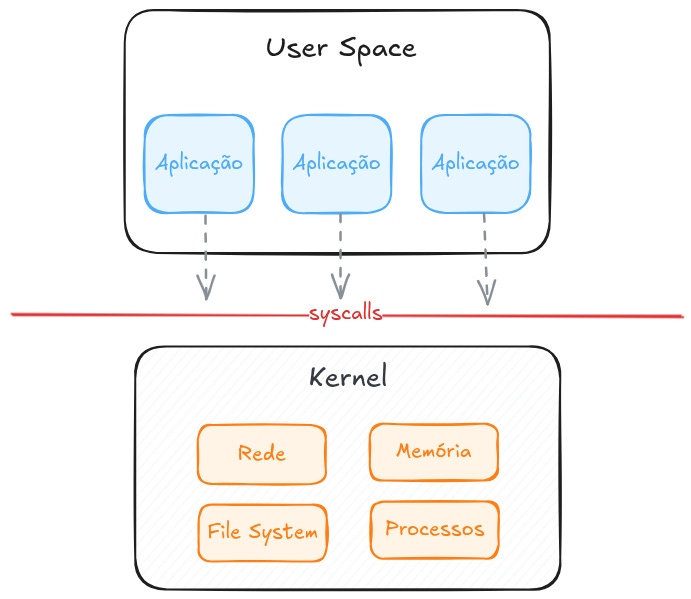
É bem difícil no dia dia utilizarmos uma interface de syscall de forma direta, pois as linguagens de programação já oferecem abstrações e bibliotecas que são muito mais fáceis de se utilizar. Por isso, muitas pessoas não fazem ideia do que o kernel está fazendo enquanto aplicações estão rodando. Para ter uma noção, veja o output de um strace durante a execução de um simples docker run.
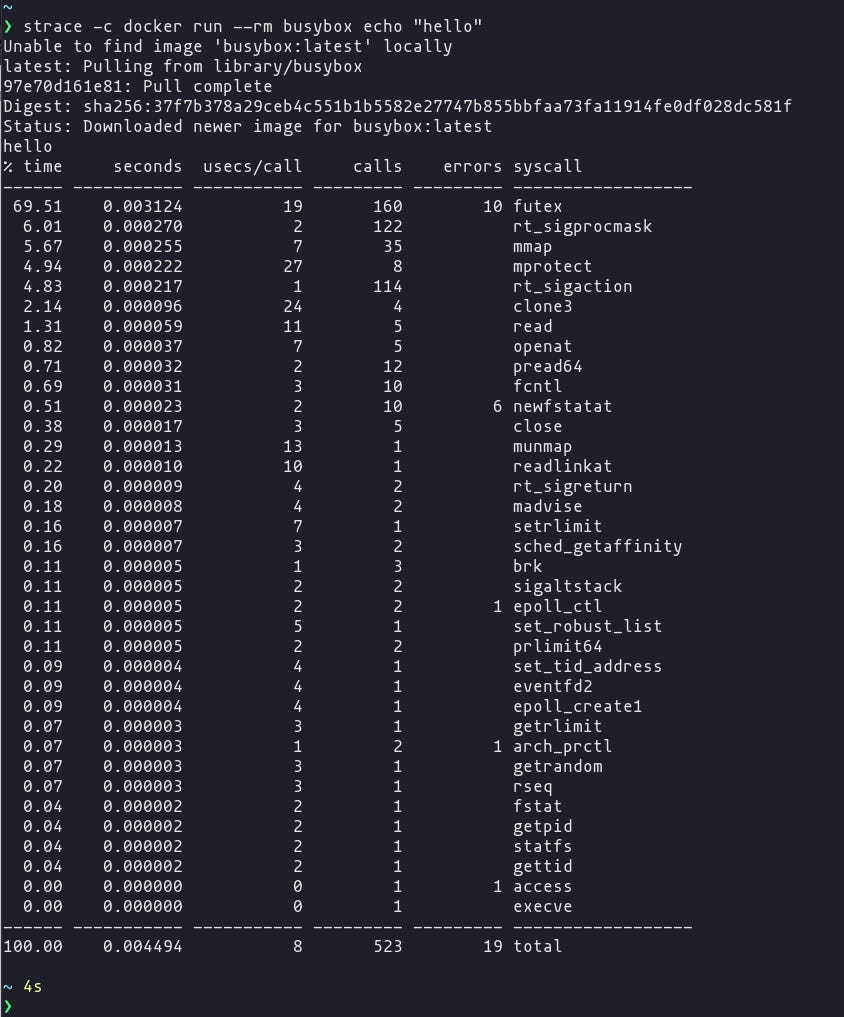
Com isso, dá pra perceber o quanto as aplicações “dependem” do kernel e com eBPF é possível adicionar instrumentações nele para entender e ter todos esses insights. Por exemplo, se você interceptar syscalls em operações de arquivos, você saberá exatamente quais arquivos foram manipulados.
Programas eBPF podem ser carregados (e descarregados) de forma dinâmica do kernel e uma vez que eles são “attachados” a um evento, esse programa sempre será acionado por esse evento independente do que o causou. Por exemplo, se você “attachar” um programa a uma syscall ao abrir arquivos, esse programa será acionado sempre que qualquer programa tentar abrir um arquivo.
Isso significa que utilizar ferramentas de segurança e observabilidade que utilizam eBPF são um grande diferencial de ferramentas comuns, pois você terá visibilidade de tudo que está acontecendo no sistema. Sem contar que também é possível filtrar eventos a nível do kernel sem enviá-los ao user space, “economizando” custo de processamento. Em ambientes rodando conteineres, a visibilidade chega até os processos dentro desses conteineres, o que nos leva ao próximo tópico.
eBPF em ambientes Cloud Native
Com a adoção de soluções cloud native como Kubernetes, são utilizadas abordagens que decidem em qual servidor um determinado workload irá rodar. Obviamente, esses servidores rodam um Sistema Operaciona que possui um kernel. E aplicações em conteineres compartilham o mesmo kernel do servidor onde estão rodando, ou seja, em um cluster Kubernetes, todos os conteineres em todos os Pods em um determinado node estão utilizando o mesmo kernel. Quando esse kernel é instrumentado através de programas eBPF, todos workloads estarão visíveis para esses programas.
E ter essa visibilidade trás benefícios como:
Não é necessário mudar ou implementar bibliotecas para instrumentá-las com eBPF;
Assim que o kernel carrega um novo programa eBPF, esse programa pode observar processos de aplicações que já estão rodando.
O que comparado com soluções que utilizam sidecars, é um super diferencial, pois:
Ao usar sidecars, os Pods precisam ser reiniciados para que esse novo conteiner seja adicionado;
O tempo de inicialização do Pod é afetado;
Gerenciar vários conteineres em um Pod só trás mais complexidade;
Como ferramentas baseadas em eBPF podem ter uma visibilidade completa, pode ser mais difícil para que invasores não sejam notados. Por exemplo, imagine que um invasor consiga explorar uma vulnerabilidade em um serviço exposto e faça upload de um binário malicioso para realizar uma coleta de dados. Se sua estratégia de observabilidade ou segurança depende de agentes instalados dentro do conteiner ou de sidecars, é bem provável que esse processo passe completamente despercebido. Já com uma abordagem baseada em eBPF, é possível observar syscalls, conexões de rede e acesso a arquivos diretamente do kernel, independentemente de como o processo foi iniciado. Isso significa que esse tipo de atividade pode ser detectada sem depender de modificações no ambiente da aplicação.
Aplicações de eBPF
Como ficou claro até aqui, o eBPF permite customizar o comportamento do kernel e observar eventos em todo o sistema e reportá-los ao user space. A partir de agora vamos entrar de forma mais profunda em como o eBPF pode ser aplicado em soluções de segurança e rede.
eBPF para segurança
Como mencionei um pouco acima, syscalls são interfaces entre aplicações rodando no user space e o kernel. É possível restringir ou limitar quais syscalls uma aplicação pode fazer, e se você utiliza Docker há um bom tempo, você já deve ter esbarrado em uma ferramenta que utiliza BPF para isso, a seccomp.
O seccomp (SECure COMPuting) surgiu com o objetivo de isolar aplicações não confiáveis, limitando quais syscalls estão disponíveis para um determinado processo. Em seu modo strict, apenas syscalls como read(), write(), _exit() e sigreturn() são permitidos, o suficiente para aplicações extremamente limitadas. Para oferecer maior flexibilidade, foi criado o seccomp-bpf, que usa filtros baseados em BPF para permitir ou bloquear syscalls dinamicamente com base em algumas configurações e os filtros são executados toda vez que uma syscall é chamada.
Ferramentas como Falco, ampliam essa abordagem ao usar eBPF para rastrear syscalls de processos já em execução, sem a limitação de aplicar políticas somente na inicialização. O Falco permite definir regras que geram alertas quando comportamentos suspeitos são detectados, usando drivers baseados tanto em módulo de kernel quanto em eBPF.
eBPF em soluções de rede
Quando pensamos em soluções de rede baseadas em eBPF, a primeira que vem a mente é o Cilium, que utiliza eBPF como plataforma para gerenciar toda parte de rede em clusters Kubernetes, provendo funcionalidades como balanceamento de carga, criptografia, observabilidade e muito mais. Outro grande exemplo é a Cloudflare, que utiliza eBPF em soluções conta DDoS.
E ao falarmos em rede, vale dar uma breve explicação sobre XDP (eXpress Data Path). O XDP é uma tecnologia para processamento de pacotes de rede, que executa programas no ponto mais “baixo” possível da stack de rede. Ele é utilizado em aplicações como:
Firewall de baixa latência, que inspeciona cada pacote assim que ele chega à interface de rede;
Mitigação de ataques DDoS ao monitorar a taxa de pacotes por IP de origem, por exemplo, se um IP exceder um certo limite em um intervalo de tempo, os pacotes serão descartados;
Pacotes malformados podem explorar vulnerabilidades (Packet of Death) no kernel, causando instabilidades ou até a paralização do sistema. Um programa XDP pode inspecionar padrões suspeitos (como headers inválidos ou tamanhos inconsistentes) e descartar o pacote antes que ele chegue de fato no kernel.
Além disso, programas XDP não são limitados a “apenas” inspecionar conteúdos de pacotes de rede, eles também podem modificar o conteúdo desses pacotes. Outro fato interessante é que atualmente já existem placas de rede (interfaces) que suportam XDP Offload, onde os programas eBPF são executados no próprio processador da placa, ou seja, um pacote pode ser dropado ou redirecionado antes mesmo de chegar ao kernel do sistema e não gastar ciclos de CPU do servidor de forma desnecessária, o que pode resultar em melhoras significativas em performance.
eBPF e a stack de rede do Kubernetes
Esse não é o ponto central do post, mas acredito que seja bom exemplificar como eBPF pode ajudar a melhorar o tráfego para (e entre) workloads rodando no Kubernetes.
Um Pod no Kubernetes, é um grupo de conteineres que compartilham o mesmo namespace do kernel e cgroups, o que isola Pods um dos outros e do servidor/node onde eles estão rodando.
Geralmente (isso vai variar de ambiente pra ambiente), um Pod tem seu próprio namespace de rede e seu endereço IP, o que significa que o kernel tem uma stack de rede para cada namespace, separando a rede do servidor/node de outros Pods. Como mostro abaixo, o Pod é conectado ao servidor/node por uma conexão Ethernet virtual.
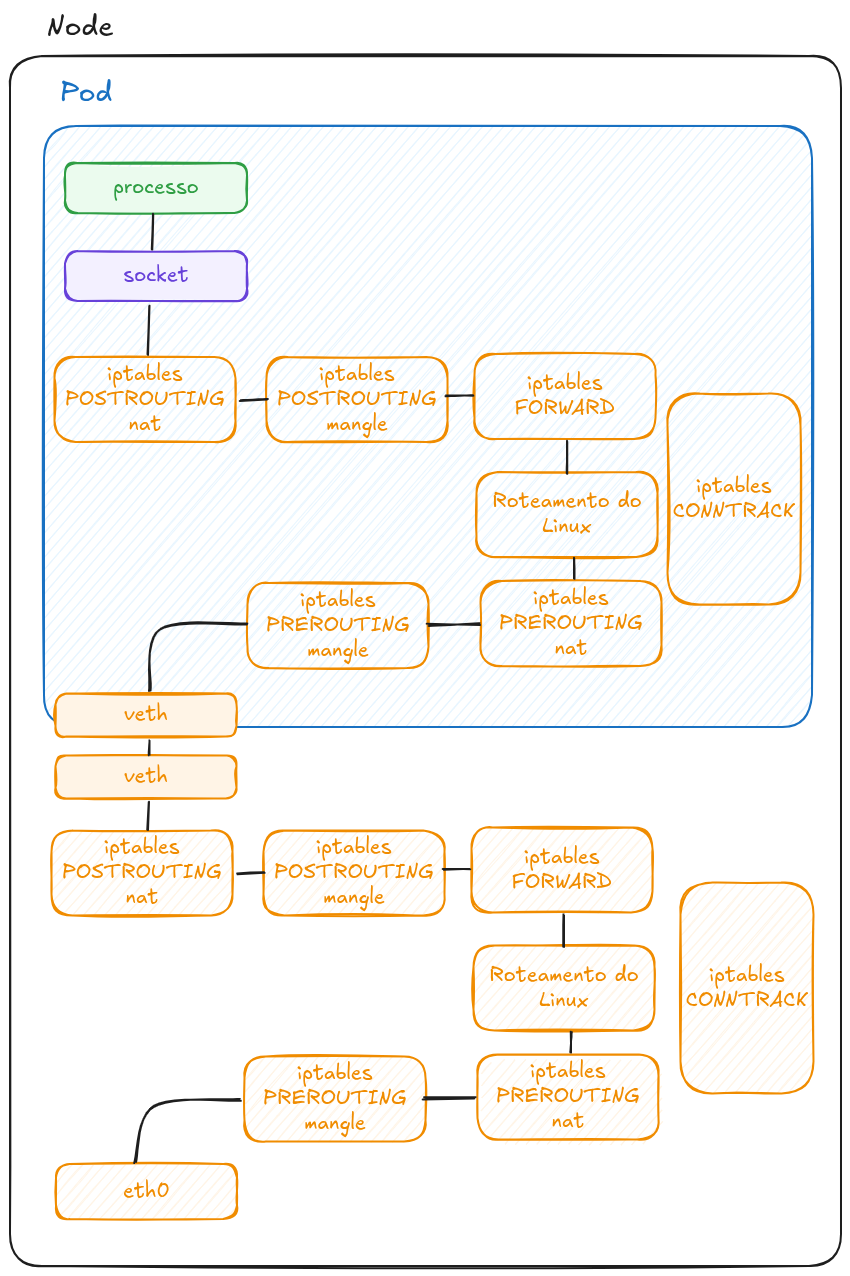
Nota-se que pacotes que vem de fora do node tem que trafegar por toda a stack de rede daquele servidor, até a interface virtual e posteriormente até a rede do Pod e consequentemente toda a stack de rede do namespace do Pod até chegar na aplicação.
Para mais contexto sobre iptables, recomendo dar uma lida nesse belo material sobre o tema.
Essas duas stacks estão no mesmo kernel, certo? Então podemos concluir que o pacote está fazendo o mesmo caminho duas vezes. Com isso, teremos uma latência mais alta. Uma solução para esse cenário seria utilizar o Cilium e substituir toda carga duplicada de roteamento do kernel e do iptables, uma vez que o eBPF é uma solução mais inteligente pra isso.
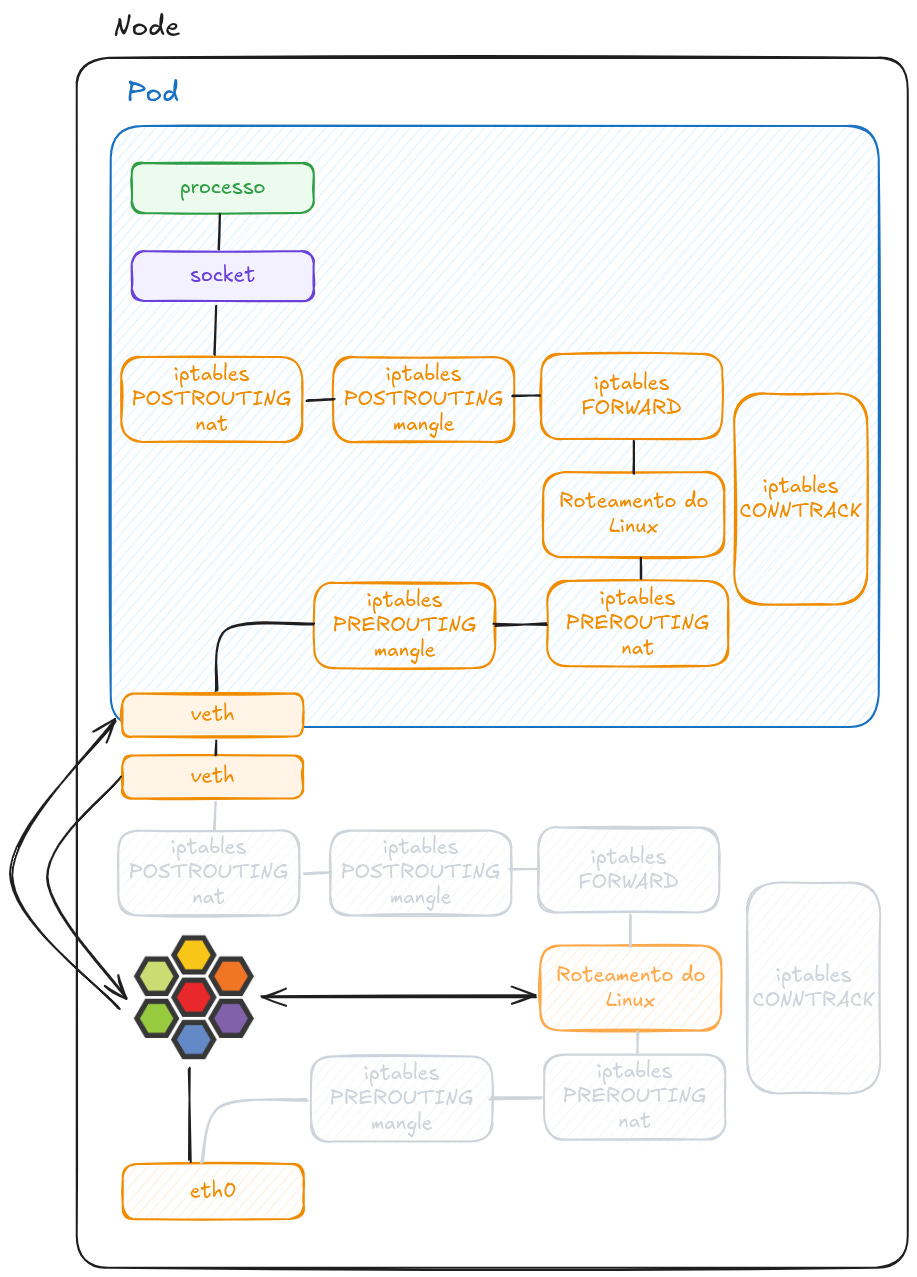
Mas qual o real motivo de evitar a utilização de iptables? O componente kube-proxy implementa uma load balancer que permite que vários Pods respondam requisições enviadas a um Service e por baixo dos panos o kube-proxy utiliza iptables.
Como muito de vocês sabem, existe a possibilidade de utilizar plug-ins de CNI (Container Network Interface) que implementam novas funcionalidades em toda camada de rede de um cluster, porém, a grande maioria ainda utiliza regras de iptables que trabalham na camada 3 e 4 (Rede e Transporte) e quando essas regras precisam ser atualizadas elas podem demorar e muito - o trecho do vídeo abaixo explica o motivo.
Então devido a utilização de eBPF pelo Cilium, toda a configuração de regras, conntrack e balanceamento de carga são armazenadas em hash table maps, que possibilitam essas operações escalar de forma muito melhor.
Finalizando
Não só eBPF, mas como o Cilium, são tecnologias que vão muito além de um post. O tema é vasto e uma coisa é entender o funcionamento macro e outra coisa é entender criando programas eBPF e implementando o Cilium. Se rolou um interesse mais e gostaria que eu abordasse mais sobre o assunto, deixe um comentário ou me procure no LinkedIn para batermos um papo.
Existe também um Substack muito interessante só sobre eBPF, chamado eBPF Chirp. Vale a pena conferir.
Até a próxima!