
Systems Performance - Overview
Introdução à Performance de Sistemas: Fundamentos e Boas Práticas


Essa é a primeira parte de uma série de posts sobre performance de sistemas, um tópico que sempre chamou minha atenção e algo que tenho estudado bastante nos últimos tempos.
A ideia desse primeiro artigo é trazer uma introdução ao tema, falar um pouco sobre onde SRE se encaixa nisso, os desafios e observabilidade.
Performance de Sistemas
Quando falamos sobre performance de sistemas, precisamos ter em mente que a disciplina contempla todos os componentes de um computador, ou seja, hardware e software, até mesmo tudo que está no fluxo de dados como dispositivos de armazenamento até a aplicação. Em sistemas distribuídos, essa abrangência inclui vários servidores e serviços replicados.
Como uma boa prática é interessante ter um diagrama do seu ambiente mostrando tudo isso, se você não tem ainda, pode ser uma ótima hora para começar agora, desta forma será mais fácil compreender as conexões ou relacionamentos entre os componentes e garantir que você tenha a visão do todo.
Ao final do dia, será possível entender a performance de sistemas e garantir uma melhor experiência para o usuário final. Seja reduzindo latência, custo de processamento, otimização de queries, e redução de saltos na rede.
A figura abaixo mostra uma stack super simples de um aplicação rodando em um único servidor.

Atividades e papéis
A análise de performance de sistemas envolve uma série de atividades que podem (e devem) ser feitas por diversos profissionais de forma holística, independente de suas funções e especialidades, pois a composição de sistemas complexos necessita de integração contínua e colaborativa de diversas disciplinas. Equipes compostas por pessoas SysAdmin, SREs, SWEs, analistas de rede, DBAs são um bom exemplo de equipes multidisciplinares. O ideal é que a análise de performance seja apenas uma parte do dia a dia de trabalho das equipes, podendo atuarem também, de forma mais eficaz na maioria dos casos. Entretanto, existem empresas que contratam pessoas focadas em performance com intuito de criar ferramentas e auxiliar outros times com análises.
No mundo perfeito, sabemos que pensar em performance deveria ser algo inicial, antes mesmo da primeira linha de código, porém, grande parte desse processo é realizado posteriormente, quando o produto já está em produção ou quando um problema surge. No entanto, realizar testes e análises de performance em produção não é errado e pra isso que servem as Feature Flags, Canary Releases e Blue-Green deployments, o que nos permite controlar melhor como uma nova feature é enviada para produção e se necessário, realizar rollback para uma versão mais estável.
É possível também realizar capacity planning (planejamento de capacidade), que não se limita apenas ao hardware e software de forma isolada, as iniciativas mais eficientes desse tipo de ação são as que levam em conta a revisão de uma arquitetura de solução por completo para atender as expectativas de uso, sejam eles focados em otimização de uso intensivo ou para expectativas de negócio.
A análise de performance em produção pode envolver SREs, geralmente seguido incident reviews ou durante a escrita de postmortems, com intuito de analisar o que aconteceu, compartilhar métodos para “debugar” o problema e encontrar maneiras de prevenir incidentes no futuro. Uma boa dica aqui, é utilizar a técnica dos 5 Whys (5 porquês), onde através da aplicação de questionamentos é possível que o time encontre a causa raíz do incidente. Claro que cada empresa tem suas peculiaridades no papel do SRE, mas o correto é que alguém que esteja na frente de resiliência participe dessas análises, seja ele um SRE ou SWE.
Desafios
A análise (ou engenharia) de desempenho de sistemas é desafiadora em alguns momentos por ser subjetiva, complexa e muitas vezes envolver múltiplos problemas sem uma causa raiz clara.
Diferente de outras disciplinas, questões de desempenho podem ser difíceis de identificar e resolver, principalmente classficá-los como "bom" ou "ruim" sem metas claras. Além disso, a complexidade dos sistemas e das interações entre seus componentes torna difícil identificar e solucionar problemas de desempenho, que podem não se manifestar de maneira reproduzível em ambientes que não sejam produtivos.
Problemas de desempenho podem também podem ter múltiplas causas, onde eventos normais ocorrem simultaneamente e juntos podem criar um problema. Além disso, em sistemas mais complexos, não é raro haver vários problemas de performance simultâneas. O desafio não é tanto encontrar um problema, mas identificar quais problemas são os mais importantes. Sim, é complexo.
Para isso, a pessoa responsável pela análise deve tentar quantificar a gravidade dos problemas e estimar o potencial de melhoria, ajudando a justificar a alocação de recursos para sua resolução. E um ótimo indicador para essa quantificação, é a latência.
Latência
Latência é a medida do tempo que um sistema leva para responder a uma solicitação e é uma métrica super essencial. Por exemplo, o tempo de um clique em um site até o carregamento total da página.
Sabe aquela ideia que é melhor retornar um erro 500 do que deixar o usuário esperando? Pois é, a latência alta pode causar até perda de clientes. Além disso, a latência permite estimar o potencial de melhoria do desempenho, quantificando o impacto de fatores como leituras de disco em uma operação e indicando onde aprimoramentos podem ser realizados para aumentar a velocidade. Vamos para um exemplo:

Na imagem acima, temos uma query que leva 200ms para ser executada (isso é a latência), no qual 180ms foi só de espera para leitura de disco. Eliminando a leitura de disco, por meio de estratégias como cache, é possível reduzir o tempo de execução de 200ms para 20ms, ou seja, tornar a operação 10 vezes mais rápida
Ao contrário de outras métricas, como operações de I/O por segundo (IOPS), a latência permite estimar com clareza o impacto de mudanças no desempenho. Contudo, a latência pode ser ambígua sem qualificadores e quantitativos. Por exemplo, em redes, ela pode se referir ao tempo necessário para estabelecer uma conexão entre uma origem e um destino, ou à duração total de uma conexão considerando todo tempo de processamento até uma resposta conclusiva da operação. Tendo isso em mente, a latência nem sempre está disponível em todos os pontos do sistema. É onde entra o eBPF, permitindo medir a latência de forma mais “customizada” e ao mesmo tempo fornecendo dados detalhados sobre sua distribuição.
Observabilidade
Observabilidade é uma prática de entendimento do comportamento de um sistema por meio de observação, utilizando ferramentas como contadores, profiling e tracing. Vale ressaltar que ferramentas de load test ou stress test, que alteram o estado do sistema não são consideradas ferramentas de observabilidade. O motivo é simples, elas criam um tipo de workload com finalidade de experimentação. Em ambientes produtivos, é recomendável utilizar ferramentas de observabilidade ao invés de ferramentas de experimentação e em ambientes de teste inativos, essas ferramentas podem ser utilizadas para avaliar o desempenho do hardware.
Aplicações e o kernel geralmente fornecem dados sobre seu estado e suas atividades, como contagem de operações, bytes, medições de latência, utilização de recursos e taxas de erro. Esses dados são geralmente implementados como variáveis do tipo inteiro chamados counters (contadores), que são inseridas nas aplicações e algumas delas acumulam valores de forma contínua, o que permite lê-los em vários momentos para análise de performance e desempenho.
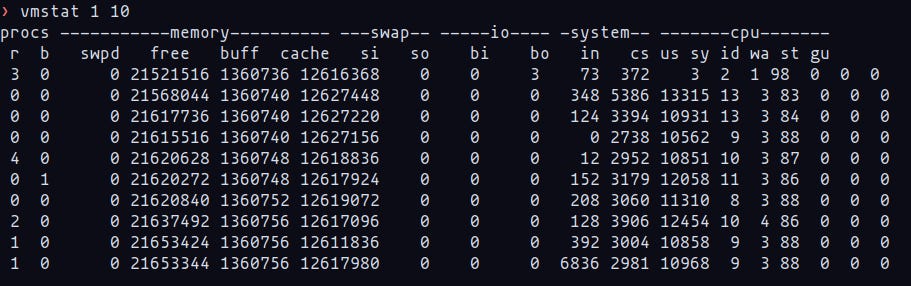
No exemplo abaixo, vemos o utilitário vmstat, que mostra um resumo de estatísticas da memória virtual baseadas nos contadores do kernel presentes no /proc. Abordarei o vmstat com mais detalhes nos próximos posts.
Em observabilidade, o termo profiling geralmente se refere ao uso de ferramentas que realizam amostragem, coletando um subconjunto de medições para criar uma visão geral do sistema. Por exemplo, CPU é um recurso comum para profiling, onde a análise é feita de forma frequente através de amostragens em intervalos de tempo durante a execução da aplicação. Uma visualização eficaz dessas amostragens são os flame graphs, que ajudam a identificar problemas de desempenho não apenas relacionados à CPU, mas também a outros aspectos como problemas de memória ao analisar o tempo de CPU em funções de alocação de memória.

Já o termo tracing se refere a um registro baseado em eventos, onde esses dados são capturados e armazenados para análise posterior ou processados em tempo. Existem ferramentas específicas para captura de traces de syscalls como o strace e o tcpdump. Essas ferramentas utilizam várias fontes para capturar os eventos, incluindo instrumentação dinâmica e estática, além da utilização do eBPF.
A instrumentação estática refere-se a pontos de instrumentação adicionados diretamente ao código-fonte da aplicação. No kernel do Linux, existem vários desses pontos que monitoram operações como I/O do disco, eventos do scheduler, syscalls e entre outros. Para software em espaço de usuário, existe uma tecnologia semelhante chamada USDT (User Statically Defined Tracing). O USDT é utilizado por bibliotecas (como a libc) para instrumentar chamadas de biblioteca e por muitas aplicações para instrumentar requisições de serviço. Já a instrumentação dinâmica, cria pontos de instrumentação enquanto o aplicação está em execução, modificando instruções na memória para inserir rotinas de instrumentação. Isso permite gerar estatísticas de desempenho em qualquer aplicação.
Finalizando
Essa foi a primeira parte de uma série de posts sobre performance de sistemas. O intuito foi dar uma introdução ao tema, abordar os principais termos e ferramentas para que possamos nos aprofundar sobre metodologias, capacity planning e benchmarking nos próximos posts.
Se você curtiu essa primeira parte, compartilhe esse post com seus colegas de trabalho e em redes sociais. Feedbacks são sempre muito bem vindos também!
Até mais. :)