
Systems Performance - Metodologias
Um deep-dive nas principais metodologias para troubleshooting de gargalos e outros problemas de performance em sistemas.


Esse é mais um post da série sobre Systems Performance. Dessa vez, irei abordar sobre metodologias, ou seja, por onde começar suas análises em ambientes e aplicações que não estão performando bem. Vou abordar sobre as principais utilizadas hoje em dia, como USE e RED, mas também comentar sobre formas mais simples que as vezes, podem dar uma luz só pelo fato de fazer algumas perguntas.
Mas antes disso, vamos dar um passo para trás e falar sobre perspectivas de análises.
Perspectivas
Existem duas perspectivas comuns para a análise de performance, cada uma direcionada a “alvos” diferentes e utilizando métricas e abordagens distintas. Essas perspectivas são: as análises de workloads e as análises de recursos.
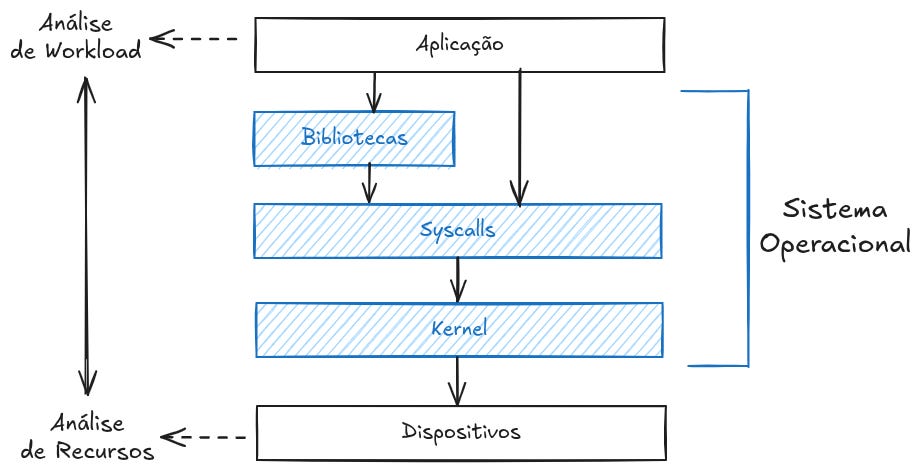
A análise de recursos começa examinando os principais componentes do sistema, como CPU, memória, discos, interfaces de rede e etc... O foco aqui está na utilização, com o objetivo de identificar quando os recursos estão próximos de atingir ou se já excederam seus limites. Alguns recursos, como a CPU, possuem métricas de utilização diretamente acessíveis. Para outros, é necessário fazer estimativas baseadas em dados disponíveis, como calcular a utilização de interfaces de rede comparando o tráfego de saída (egress) e entrada (ingress) com a largura de banda máxima.
As métricas mais adequadas para análise de recursos incluem: IOPS, Throughput, Utilização e Saturação. Vou entrar em detalhes sobre isso mais a diante.
Essas métricas revelam não apenas a carga aplicada a cada recurso, mas também o quão próximos eles estão de seus limites operacionais. Métricas adicionais, como latência, fornecem uma visão complementar, ajudando a avaliar como os recursos estão lidando com os workloads em termos de tempo de resposta. Existem ferramentas nativas no Linux como vmstat, mpstat e iostat, que fornecem dados detalhados para uma análise mais certeira.
Já a análise de workload foca no desempenho das aplicações, avaliando a carga aplicada e como a aplicação responde a ela. As principais métricas para análise são taxa de requests e latência.
Essa análise envolve examinar os atributos das requests, como o quantidade de clients, tabelas mais acessadas ou as queries mais realizadas. Isso ajuda a identificar cargas desnecessárias ou desbalanceadas. Mesmo em sistemas com baixa latência, entender os padrões de workload pode revelar algumas oportunidades de otimização.
A latência é o indicador mais importante de desempenho da aplicação, representando o tempo de resposta. Para diferentes sistemas, como bancos de dados ou servidores web, a latência equivale ao tempo para processar queries ou requisições HTTP.
Com isso alinhado, vamos nos aprofundar em algumas metodologias.
Metodologias
Ao trabalhar com aplicações e ambientes não performáticos, geralmente o primeiro desafio é: Por onde devemos começar?
Assim como mencionei no primeiro post dessa série, problemas de performance podem aparecer de qualquer lugar, software, hardware ou qualquer componente que esteja no fluxo dos dados. As metodologias de análise podem ajudar por onde iniciar a análise com processos mais efetivos.
Entendendo o problema
Entender o que de fato está acontecendo é a primeira coisa a ser feita. Não importa o tipo de problema. Com uma série de perguntas básicas, as vezes é possível chegar a uma causa e a solução do problema só respondendo essas perguntas.
O que te faz pensar que existe um problema de performance?
Essa aplicação já teve boa performance anteriormente? Se sim, há quanto tempo?
O que mudou nos últimos dias? Código? Alteração no workload? Hardware?
É um problema no tempo de resposta?
O problema está afetando outras aplicações?
Como está o ambiente? Quais libs são utilizadas? Existem versões mais novas? Qual a configuração da aplicação?
Obviamente que isso se torna cada vez mais “fluído” e natural uma vez que a senioridade da pessoa vai aumentando. Uma dica que eu dou para enriquecer ainda mais a análise é testar a hipótese de um problema com base em dados.
Outra dica que eu dou é, cuidado com o número de ferramentas ao analisar e entender o problema. Sempre que possível, tente correlacionar as métricas em um único lugar.
USE - Utilization, Saturation, Errors
O método USE é uma das abordagens para identificar gargalos e desempenho em sistemas. Ele se concentra na análise de recursos como CPUs, memória e disco, seguindo três métricas-chave:
Utilization: Mede o percentual de tempo ou capacidade que um recurso está ocupado processando algum workload. Para memória, a utilização se refere à porcentagem da capacidade total em uso.
Saturation: Indica a “pressão” sobre o recurso, geralmente manifestada por filas de espera quando o recurso não consegue atender à toda demanda.
Errors: Mede eventos de falha, incluindo operações que precisam ser repetidas ou dispositivos com falhas.
Essa metodologia prioriza a verificação rápida dessas métricas para todos os recursos do sistema, criando uma lista de "known-unknowns" quando os dados estão indisponíveis.
Uma dica aqui é a investigação de erros, que podem degradar o desempenho sem serem identificados de imediato, especialmente em sistemas que possuem algum tipo de mecanismo de recuperação automática.
No fluxograma abaixo, demonstro de forma prática como iniciar uma análise utilizando o método USE.

Erros geralmente são verificados primeiro, já que eles são rápidos e fáceis de interpretar. Saturação é verificado em um segundo passo devido a facilidade de interpretar se comparado com a Utilização, já que qualquer nível de saturação pode ser um problema.
Um ponto importante de destacar é que picos curtos de alta utilização podem causar saturação e consequentemente, problemas de desempenho, mesmo que a utilização média em intervalos maiores pareça baixa. Ferramentas de monitoramento que usam médias de 5 minutos por exemplo, podem mascarar esses picos, como no caso de CPUs que atingem 100% brevemente, gerando gargalos não detectáveis em médias mais extensas.
Assim que você tiver em mãos os recursos a serem analisados, pense nas métricas para cada um deles se baseando em utilização, saturação e erros, por exemplo:

Algumas dessas métricas podem não estar disponíveis em ferramentas padrões que já acompanham o sistema operacional e podem necessitar de uma monitoria adicional.
Gosto de pensar nessas métricas da seguinte forma:
Utilização: Geralmente utilização em 100% é um sinal de gargalo. Acima de 60% já pode ser um problema em alguns casos. Dependendo do intervalo de monitoração, ele pode esconder os picos de alta utilização;
Saturação: Qualquer nível de saturação pode ser um problema. Medir o tamanho da fila de espera ou o tempo aguardando na fila é uma boa também;
Erros: Igual a Saturação, qualquer evento de erro é válido investigar, ainda mais se a performance está degradada e os erros continuam aumentando.
E recursos de sistemas?
Alguns recursos de software ou sistemas também podem ser analisados dessa forma. Isso geralmente se aplica a componentes menores e não aplicações inteiras, vamos aos exemplos:
Thread pools: A Utilização pode ser definida pelo tempo que as threads estavam ocupadas (busy) processando algum workload, já a Saturação pode ser definida pela quantidade de requests aguardando serem processadas;
Capacidade de thread ou processo: O sistema pode ter uma quantidade limitada de processos ou threads, o qual o uso naquele momento pode ser definida para Utilização. Já o tempo de espera de alocação de novas threads pode indicar Saturação e por fim Erros é quando a alocação falhou, no caso gerando um
cannot fork;Capacidade do file descriptor: Similar a capacidade de threads e processos, porém para file descriptors.
Em casos de microsserviços rodando no Kubernetes por exemplo, podemos pensar da seguinte forma:
Utilização: A média de utilização de CPU se comparado ao total de CPU disponível no cluster;
Saturação: A diferença entre o p99 e a média da latência;
Erros: Erros de requests.
Porém, há uma metodologia que foi criada especificamente para serviços, a RED.
RED - Request Rate, Errors, Duration
O objetivo da RED é acompanhar métricas de serviços, já que podemos verificar a saúde do sistema com a perspectiva do usuário.
As métricas são:
Request rate: O número de requisições por segundo;
Errors: A quantidade de requisições que falharam;
Duration: O tempo que levou para completar uma requisição.
As vantagens de utilizar a metodologia RED são similares ao USE. É fácil e rápido de identificar problemas. Vale ressaltar que ambas metodologias se complementam, você pode utilizar a USE para saúde de recursos do servidor e RED para aplicação.
Medir a taxa de requisições (request rate), dá uma boa ideia de onde começar a investigar o problema, se é um problema de performance ou é pela quantidade (de requisições) ou um problema arquitetural (meu post anterior fala um pouco disso). Se a taxa de requisições está estável, mas a duração delas está aumentando possivelmente é um problema de arquitetura. Se ambos aumentam, então o problema pode ser o workload.
Investigando o workload
Workloads podem ser caracterizados respondendo algumas perguntas:
Quem causou a carga? Foi um processo, usuário (aplicação) ou um IP remoto?
Por que essa carga excessiva? Existe um stack trace para análise?
Quais são as características dessa carga? Aumento de IOPS, throughput?
Como a carga muda conforme o tempo? Existe um padrão? É um padrão diário?
Imagine este cenário: você está investigando um problema de desempenho em microsserviços em um cluster Kubernetes. O tráfego esperado deveria vir de serviços internos, mas você decide verificar as métricas de rede. Para sua surpresa, descobre que um único nó está recebendo uma quantidade anormal de conexões de outro serviço, enquanto os demais estão praticamente ociosos. Após uma investigação mais profunda, percebe que um erro na configuração do service discovery está direcionando todas as requisições para apenas um pod, causando um hotspot e degradando o desempenho da aplicação.
Five whys
Um método adicional que você pode utilizar é o Five Whys, onde você se pergunta “Por que?” por cinco vezes (ou mais) até encontrar a causa raíz.
Uma instância de banco de dados começou a degradar performance conforme a quantidade de queries aumentou. Por que?
É um problema de IO devido a paginação de memória. Por que?
A utilização de memória aumentou. Por que?
O alocador está consumindo mais memória do que o previsto. Por que?
A versão do banco de dados tem um bug no alocador de memória.
Esse é um caso real que pode ser resolvido atualizando a versão do banco de dados. O problema foi encontrado se questionando e indo a fundo para entender a causa raíz.
Anti-patterns
Para fechar o post, vale mencionar dois anti-patterns muito comuns de acontecer. Principalmente se quando existem silos muito bem definidos na estrutura de engenharia da empresa.
O primeiro deles é quando a pessoa responsável por solucionar um problema, vai tentando adivinhar onde está a causa raíz e sai mudando várias configurações, alocação de recursos, atualização de libs até o problema desaparecer. Além de ser um processo custoso, a pessoa pode ter alterado algo que não faz o menor sentido.
Outro exemplo que é clássico é jogar o problema no colo do colega. Imagine o seguinte cenário, a pessoa começou a analisar um problema, sem nenhuma análise muito profunda, ela acha que o problema pode ser a rede. Por ter um time especializado naquele tema, ela joga o problema para o time. Caso o problema não seja aquele, a pessoa volta para a análise desde o início e continua jogando o problema para os outros.
A dica nesse caso para não se tornar dono de um problema que não é seu, peça a pessoa que está analisando o problema, evidências que comprovem o que ela está dizendo.
Conclusões
Acredito que abordei nesse post a maioria dos temas sobre metodologias que conheço e utilizo. Minhas dicas para SREs e SWEs que gostam do tema é, tenham em mente as metodologias como USE e RED. Elas fornecem um caminho estruturado para identificar e solucionar gargalos. Além disso, a abordagem investigativa baseada em perguntas e técnicas como Five Whys ajudam a enxergar além dos sintomas, chegando à verdadeira causa dos problemas.
No final das contas, resolver problemas de performance é tanto uma questão técnica quanto um exercício de análise crítica. Não tenha medo de perguntar e questionar. Ferramentas e métricas são essenciais, mas uma abordagem baseada em evidências é o que vai diferenciar um troubleshooting eficaz de um processo meia boca.
Até a próxima!